



I. Introduction▲
Souvent qualifiée de Big Data, l'explosion des données qui a accompagné la révolution d'Internet ces dernières années a provoqué un changement profond dans la société, marquant l'entrée dans un nouveau monde « numérique » dont l'un des piliers technologiques est Hadoop. Il devient donc important pour tout un chacun de comprendre les principes de base d'Hadoop. Ce cours abordera les thèmes suivants :
- l'architecture de l'infrastructure d'Hadoop ;
- le fonctionnement d'Hadoop ;
- et le MapReduce.
II. Contexte de création d'Hadoop▲
Pensez à toutes les données que nous avons aujourd'hui : déjà, en 2012, IDC postulait que de 2005 à 2020, le volume de données croîtrait d'un facteur de 300, de 130 exaoctets à 40 000 exaoctets, soit 40 trillions de gigaoctets, ce qui représente plus de 5200 gigaoctets créés pour chaque homme, femme et enfant en 2020. Actuellement, le volume des données en circulation connaît une démultiplication permanente : 5 exaoctets de données sont désormais produits tous les deux jours, soit le même volume que l'ensemble des données produites de l'aube de la civilisation à 2003. En 2014, 90 % de toutes les données jamais générées par l'homme l'ont été au cours des deux dernières années ; Cisco renchérit ce constat lorsqu'il prédit que le trafic IP global annuel serait de 1,3 zettaoctet en 2016. Cet accroissement dans le trafic réseau est attribué à l'accroissement du nombre des smartphones, tablettes et autres appareils connectés à Internet, à la croissance des communautés d'utilisateurs Internet, à la croissance de la bande passante, à la rapidité offerte par les opérateurs de télécommunication, et à la disponibilité et à la connectivité du Wi-Fi. Ne parlons même pas de la variété d'actifs de données créées !
L'échelle de cette croissance de données surpasse la capacité raisonnable des technologies traditionnelles, précisément les systèmes de gestion de bases de données relationnelles (SGBDR), ou même la configuration matérielle typique supportant les accès à ces données. Plus encore, les données canalisées vers le réseau Internet créent de la pression pour la capture cohérente et rapide de ces données. Les entreprises doivent trouver le moyen de maîtriser et de pouvoir efficacement traiter ces données pour continuer à servir fidèlement leur clientèle et rester compétitives. Google fait partie des entreprises qui ont très tôt ressenti le besoin de gérer efficacement les gros volumes de données liés aux requêtes faites par les utilisateurs. Rappelons que le moteur de recherche de Google doit restituer en temps quasi réel le résultat de 3 millions de recherches effectuées par minute. Pour répondre à cette exigence, Google doit indexer toutes les pages web qui constituent Internet et rechercher à l'intérieur de chacune de ces pages les mots qui sont demandés par l'utilisateur. Le nombre de sites Internet dans le monde aujourd'hui est estimé à plus de 1 milliard avec une croissante de 5,1 % (estimation faite par Netcraft), sachant qu'au-delà de 5 secondes d'attente, l'utilisateur considère que la requête a échoué et passe à autre chose. Résoudre ce problème ne peut se faire ni avec les approches de centralisation des données dans un seul serveur comme on l'a fait dans le passé, et ni avec les approches centralisées de traitement in-memory. Il est dès lors indispensable de penser à d'autres approches, et c'est là où Hadoop entre en scène.
II-A. Approche conceptuelle d'Hadoop▲
Pour répondre à ces challenges, l'idée de Google est de développer une approche conceptuelle qui consiste à distribuer le stockage des données d'une part et à paralléliser le traitement de ces données sur plusieurs nœuds d'une grappe de calcul (un cluster d'ordinateurs) d'autre part. L'emploi d'une grappe de calcul n'est pas anodin. En effet, tout en étant l'infrastructure qui sert de support au traitement massivement parallèle, son utilisation permet de profiter des rendements d'échelle engendrés par la baisse des coûts des ordinateurs. Ainsi, la croissance des données est gérée en augmentant simplement les nœuds dans le cluster. Nous présenterons plus loin les caractéristiques intrinsèques du cluster d'ordinateurs. Cette approche conceptuelle a été adoptée par le marché et est à la base de toutes les technologies Big Data actuellement.
II-A-1. Au niveau du traitement ▲
Google décide de découper le problème d'indexation des pages web en sous-tâches ou sous-problèmes qui seront distribués dans le cluster pour exécution. Pour ce faire, Google décide de construire un index inversé par mot-clé contenu dans chaque page web. Pour faire simple, un index inversé correspond à la page d'index d'un livre ; il est constitué des mots-clés, avec pour chaque mot-clé ses différentes localisations dans tout le document. Ainsi, chaque fois que vous recherchez un mot, vous pouvez vous servir de l'index pour identifier la ou les pages où le mot que vous cherchez se situe, cela vous évite de fouiller tout le document page par page pour retrouver le mot. Aujourd'hui, la recherche Internet fonctionne selon ce principe. Le moteur de recherche constitue une base d'index inversés pour chaque mot. Cependant, construire un index inversé n'est pas aussi simple que ça en a l'air. Pour que vous ayez une image claire du problème, prenons l'exemple d'une page web contenant 5000 mots. Le moteur de recherche doit indexer les 5000 mots. Indexer 1000 pages web contenant chacune 5000 mots demande la construction d'un index inversé de 5 000 000 mots (1000 × 5000). Pour construire l'index inversé, Google passe par un raisonnement en trois phases consécutives : la première phase, appelée par Google la phase Map, consiste à assigner à chaque nœud du cluster la tâche d'attribuer à chaque mot de la page web un indice correspondant à la page dans laquelle il est. Cet indice peut être le titre de la page, le numéro de la page, bref n'importe quel élément qui permet d'identifier la page de façon unique parmi toutes les pages qui constituent tout le site web. Cette tâche s'exécute parallèlement (en même temps) dans tout le cluster. La deuxième étape, appelée par Google le Shuffle, consiste pour chaque nœud à trier par ordre alphabétique les mots auxquels il a affecté un index. Cette étape est intermédiaire et permet de faciliter le travail effectué par la troisième phase. La troisième et dernière phase, appelée par Google le Reduce, consiste pour chaque mot dans l'ensemble des nœuds du cluster, à regrouper l'ensemble de ses indices. Ainsi, on obtient l'index inversé.
II-A-2. Au niveau du stockage ▲
Google décide de ne pas centraliser le stockage de toutes les pages Internet vers un seul serveur pour la construction des index inversés. De toute façon, cette approche n'est pas envisageable vu que le volume de données généré aujourd'hui dépasse largement la capacité des serveurs traditionnels. Comme la tâche de construction des index est partagée entre les nœuds du cluster, les fichiers contenant les mots (les pages web) doivent être divisés et chaque morceau de fichier doit être stocké de façon redondante sur le disque dur des nœuds du cluster de sorte que si un nœud tombe en panne tout au long du traitement, cette panne n'affecte pas les autres tâches. Techniquement, le stockage de fichiers sur un disque dur se fait à l'aide de ce que l'on appelle un système de fichiers (File System). Le système de fichiers est unique par ordinateur, ce qui pose problème dans un cluster où l'ensemble des nœuds doit être vu comme un seul ordinateur. Pour résoudre ce problème et gérer la redondance des données sur plusieurs disques durs, Google met sur pied un nouveau type de système de fichiers appelé « système de fichiers distribués » (Distributed File System - DFS), qui est installé sur le cluster. La figure suivante résume le travail de construction d'index inversés par le raisonnement en trois phases de Google.
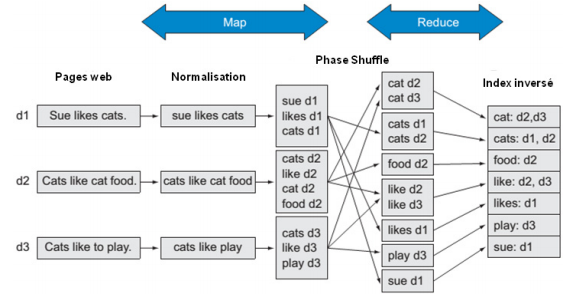
C'est par cette approche conceptuelle que Google arrive à gérer son problème d'indexation de pages web et à tirer avantage des données générées dans le numérique. Le découpage des traitements en plusieurs tâches et la parallélisation de ces tâches sur un grand nombre de nœuds se font à l'aide du modèle en trois étapes présentées précédemment que Google a baptisé MapReduce ; la distribution, le stockage et la redondance des fichiers sur le cluster se font à l'aide du système de fichiers distribués mis au point par Google et baptisé Google File System (GFS). Ces deux éléments à l'origine étaient utilisés en interne chez Google. Plus tard, un ingénieur de l'entreprise, Doug Cutting, va implémenter en Java le MapReduce et le GFS, et donner le nom d'une des peluches de son fils à cette implémentation : Hadoop. Le HDFS (Hadoop Distributed File System) est son système de fichiers distribués, l'équivalent du GFS. Depuis 2009, le projet Hadoop a été repris par la fondation Apache et est officiellement devenu un framework open source. Hadoop et le HDFS forment aujourd'hui la nouvelle infrastructure technologique de l'ère numérique.
III. Fonctionnement d'Hadoop▲
Comme vous l'avez vu plus haut, le MapReduce est une approche conceptuelle, elle a besoin d'être implémentée pour être utilisée. Hadoop répond à cette demande : Hadoop est l'implémentation la plus populaire et la plus mature du MapReduce sur le marché. En réalité, Hadoop est un ensemble de classes écrites en Java pour la programmation des tâches MapReduce et HDFS dont les implémentations sont disponibles en plusieurs autres langages de programmation. Il y a par exemple des implémentations MapReduce en Scala, et C#. Ces classes permettent à l'analyste d'écrire des fonctions Map et des fonctions Reduce qui vont traiter les données sans que l'analyste ait à savoir comment ces fonctions sont distribuées et parallélisées dans le cluster. Dans ce point, vous allez comprendre le fonctionnement d'Hadoop, les étapes d'exécution d'un programme MapReduce dans un cluster Hadoop et la façon dont il est parallélisé.
III-A. Terminologie d'Hadoop▲
Avant de parler de l'exécution des jobs MapReduce dans Hadoop, nous allons en présenter la terminologie. Un Job MapReduce est une unité de travail que le client veut exécuter. Il consiste en trois choses : le fichier des données à traiter (Input file), le programme MapReduce, et les informations de configuration (Métadonnées). Le cluster exécute le job MapReduce en divisant le programme MapReduce en deux tâches : les tâches Map et les tâches Reduce. Dans le cluster Hadoop, il y a deux types de processus qui contrôlent l'exécution du job : le jobtracker et un ensemble de tasktrackers. Le jobtracker c'est le processus central qui est démarré sur le nœud de référence (le Name Node), il coordonne tous les jobs qui s'exécutent sur le cluster, gère les ressources du cluster et planifie les tâches à exécuter sur les tasktrackers. Les tasktrackers ce sont les processus qui traitent le programme MapReduce de l'analyste, ils sont démarrés au niveau des nœuds de données, exécutent les tâches Map ou Reduce et envoient des rapports d'avancement au jobtracker, qui garde une copie du progrès général de chaque job. Si une tâche échoue, le jobtracker peut le replanifier sur un tasktracker différent. En fait, le jobtracker désigne le nœud de référence et le process Master qui y est démarré, tandis que le Tasktracker désigne un nœud de données et le process Worker qui y est démarré. La figure ci-après illustre le rapport entre le jobtracker et les tasktrackers dans le cluster.
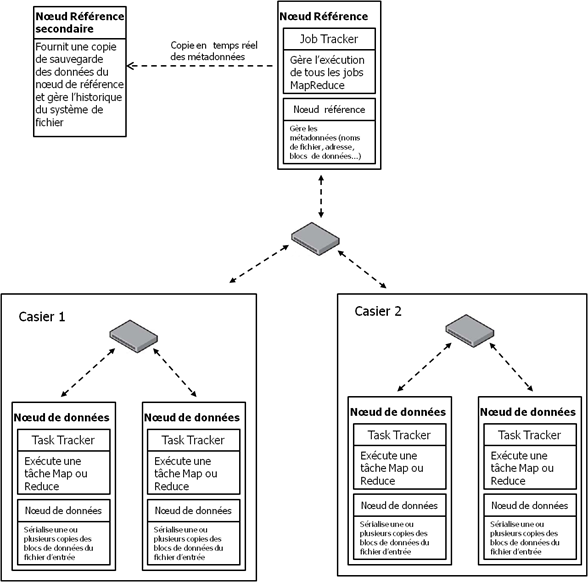
Chaque nœud possède une partie stockage et une partie traitement. La partie stockage est assurée par le nœud, tandis que la partie traitement est effectuée par le processus (Worker ou Master) qui est démarré sur le nœud. Dans la terminologie Hadoop le nom du processus est associé à la machine, on parle de jobtracker et tasktracker.
Maintenant que nous avons réglé le problème de terminologie, regardons ensemble la façon dont le MapReduce y est exécuté.
III-B. Détails d'exécution d'un modèle de calcul dans Hadoop ▲
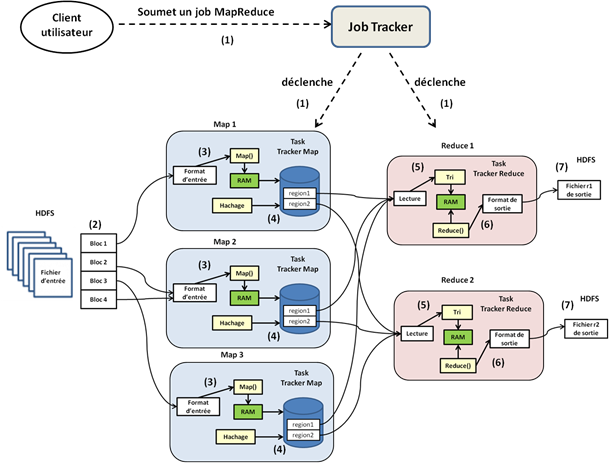
Même si Hadoop est l'implémentation du MapReduce, depuis sa version 2 et +, il a la capacité d'exécuter plusieurs modèles de calcul sur le cluster. Cela est possible grâce à un gestionnaire de ressources tel que MESOS ou YARN. Par contre, tous les modèles de calcul sont exécutés de la même façon par Hadoop. Dans ce point, nous allons illustrer les étapes d'exécution d'un modèle de calcul sur Hadoop avec le MapReduce. Par ailleurs, soyez attentifs. Le traitement MapReduce écrit par l'utilisateur s'appelle un job MapReduce dans la terminologie du cluster Hadoop et s'exécute en sept étapes :
- Au départ, l'utilisateur configure le Job MapReduce : il écrit la fonction Map, la fonction Reduce, spécifie le nombre de tâches Reduce que nous appellerons r, le format de lecture du fichier d'entrée, le format de sortie des r fichiers Reduce, éventuellement la taille des blocs du fichier d'entrée et le facteur de réplication . Une fois que tout cela est fait et qu'il déclenche l'exécution du job, le jobtracker démarre les r tasktrackers qui vont effectuer les r tâches Reduce que l'utilisateur a spécifiées ;
- Le HDFS découpe le fichier d'entrée en M blocs de taille fixe, généralement 64 Mo par bloc (sauf si l'utilisateur a spécifié une taille de bloc différente à la première étape). Ensuite, le HDFS réplique ces blocs selon le facteur de réplication définie par l'utilisateur (trois par défaut) et les distribue de façon redondante dans des nœuds différents dans le cluster. Le fait de diviser le fichier d'entrée en blocs de taille fixe permet de répartir de façon équilibrée la charge de traitement parallèle entre les nœuds du cluster, ce qui permet au traitement de s'achever à peu près au même moment dans l'ensemble des nœuds du cluster ;
- Par défaut, le jobtracker déclenche M tasktrackers sur les M nœuds de données dans lesquels ont été répartis les M blocs du fichier d'entrée, pour exécuter les tâches Map, soit un tasktracker Map pour chaque bloc de fichier. Chaque tasktracker lit le contenu du bloc de ficher par rapport au format d'entrée spécifié par l'utilisateur, le transforme par le processus de hachage défini dans la fonction Map en paires de clés/valeurs. Ce processus de hachage s'effectue en mémoire locale du nœud ;
- Périodiquement, dans chaque nœud, les paires de clés/valeurs sont sérialisées dans un fichier sur le disque dur local du nœud. Ensuite ce fichier est partitionné en r régions (correspondant aux r tâches Reduce spécifiées par l'utilisateur) par une fonction de hachage qui va assigner à chaque région une clé qui correspond à la tâche Reduce à laquelle elle a été assignée. Les informations sur la localisation de ces régions sont transmises au jobtracker, qui fait suivre ces informations aux r tasktrackers qui vont effectuer les tâches Reduce ;
- Lorsque les r tasktrackers Reduce sont notifiés des informations de localisation, ils utilisent des appels de procédures distantes (protocole RPC) pour lire depuis le disque dur des nœuds sur lesquels les tâches Map se sont exécutées, les régions des fichiers Map leur correspondant. Ensuite, ils les trient par clé. Notez au passage que le tri s'effectue en mode batch dans la mémoire du tasktracker Reduce. Si les données sont trop volumineuses, alors cette étape peut augmenter de façon significative le temps total d'exécution du job ;
- Les tasktrackers Reduce itèrent à travers toutes les données triées et pour chaque clé unique rencontrée, ils la passent avec sa valeur à la fonction Reduce écrite par l'utilisateur. Les résultats du traitement de la fonction Reduce sont alors sérialisés dans le fichier ri (avec i l'indice de la tâche Reduce) selon le format de sortie spécifié par l'utilisateur. Cette fois-ci, les fichiers ne sont pas sérialisés dans le disque dur du nœud tasktracker, mais dans le HDFS, ceci pour des raisons de résilience (tolérance aux pannes) ;
- Le job s'achève là, à ce stade, les r fichiers Reduce sont disponibles et Hadoop applique en fonction de la demande de l'utilisateur, soit un « Print Écran », soit leur chargement dans un SGBD, soit alors leur passage comme fichiers d'entrée à un autre job MapReduce.
La figure suivante récapitule en visuel ces sept étapes.
IV. Note de la rédaction developpez.com ▲
Ce cours est un extrait du livre intitulé Hadoop : Devenez opérationnel dans le monde du Big Data.
La rédaction de développez.com tient à remercier Juvénal CHOKOGOUE qui nous a autorisés à publier ce cours.
Nous remercions également Claude LELOUP pour la relecture orthographique.