



I. Introduction▲
Une des solutions conceptuelles au problème de traitement de masses de données majoritairement utilisées dans le Big Data est la suivante : les traitements/calculs sont divisés en tâches et leur exécution est parallélisée dans un cluster d'ordinateurs tolérant aux pannes. La tolérance aux pannes est fournie par un tout nouveau type de système de fichiers appelé « Système de Fichier Distribué » (DFS). Le découpage et le parallélisme des tâches se fait à l'aide du modèle de programmation MapReduce (qui consiste à dispatcher les traitements puis à regrouper les résultats). Une application générique de gestion de ressources comme YARN ou MESOS permet d'aller au-delà de MapReduce et d'utiliser d'autres modèles de calcul sur le cluster. Hadoop est une implémentation de MapReduce qui s'avère être la plus populaire et la plus mature du marché, et en passe de devenir le standard de facto du Big Data.
Nous pouvons dire, sans prendre de risque, que Hadoop va devenir la plateforme de traitement de données par défaut des utilisateurs, un peu comme Excel est progressivement devenu le logiciel par défaut d'analyse de données. Problème : à la différence d'Excel, Hadoop n'a pas été à la base conçu pour être utilisé par les « utilisateurs métier », mais par les développeurs.
Or, selon la loi de Metcalfe, « la valeur d'un standard est proportionnelle au carré du nombre de systèmes qui l'utilisent ». Nous pouvons contextualiser cette citation en disant que « la valeur d'une technologie est proportionnelle au carré du nombre de personnes qui l'utilisent ». En d'autres termes, l'adoption à grande échelle et le succès de Hadoop ne dépendent pas d'une minorité de développeurs, mais des utilisateurs métier !
La fondation Apache a bien compris ce paradigme et c'est pourquoi, depuis qu'elle a repris Hadoop en 2009, elle s'évertue à rapprocher Hadoop le plus possible du langage SQL (Structurd Query Language).
Pourquoi spécialement le SQL ? Pour différentes raisons : parce que le SQL est le langage le plus employé des utilisateurs métier pour la manipulation des données. Parce que les entreprises utilisent de plus en plus HDFS (Hadoop Distributed File System) à titre d'outil de stockage central pour toutes les données de l'entreprise, et que la majorité des outils d'exploitation de ces données (par exemple SQL Server, Business Objects, Oracle, SAS, Tableau, etc.) s'appuient sur le SQL. Par conséquent, il faut des outils capables d'exécuter le SQL directement sur HDFS.
Il existe actuellement deux grandes catégories d'outils SQL sur Hadoop : les langages d'abstractions SQL et les moteurs natifs SQL sur Hadoop. Ce papier va vous aider à écrire des requêtes dans les langages d'abstractions SQL d'Hadoop, notamment HiveQL et Pig Latin.
II. Les langages d'abstraction▲
Il y'a des raisons de croire que le MapReduce va devenir le mode normal de traitement des données dans l'ère numérique et donc que Hadoop va devenir l'outil par défaut du traitement de données. Le problème est que le MapReduce est un langage de très bas niveau, c'est-à-dire très proche de la machine, il implique que le développeur sache interagir avec le cluster, ce qui peut être très difficile pour un développeur nouveau dans le monde du traitement parallèle, ou pour des utilisateurs métiers. L'un des moyens de simplifier le développement MapReduce, et Hadoop en général consiste à fournir ce qu'on appelle un langage d'abstraction. Un langage d'abstraction est un langage à syntaxe relativement proche du langage humain qui permet d'exprimer des problèmes métiers sous forme de requêtes simples. L'abstraction vient du fait que lorsque l'utilisateur exprime son besoin sous forme d'une requête, cette requête est transformée plus bas en instructions-machine. Ainsi, le langage d'abstraction n'est en réalité qu'une couche qui masque la complexité d'expression des problèmes directement en langage de bas niveau comme le ferait un développeur. Plus le niveau d'abstraction offert par le langage est élevé, et plus on est éloigné de la machine, et plus simple il est pour les utilisateurs. La fondation Apache fournit pour le moment trois langages d'abstraction pour le MapReduce : Hive, Pig et Cascading. Ces trois langages, conçus pour un public non-développeur, permettent d'exprimer des jobs MapReduce dans un style de programmation similaire à celui du SQL, familier aux utilisateurs. Par la suite, ces langages transforment les requêtes écrites en Jobs MapReduce qui sont soumises au cluster pour exécution. Globalement, Hive offre un langage de plus haut niveau d'abstraction que Pig et Pig offre une abstraction de plus haut niveau que Cascading. Dans cet article, nous n'étudierons uniquement que le Hive et Pig. Cascading étant de trop bas niveau pour les analystes métier uniquement habitués au SQL. La figure suivante illustre la relation entre le niveau d'abstraction des langages, la proximité de l'utilisateur au MapReduce, et la complexité de programmation. Bien évidemment, plus on éloignera l'utilisateur métier du MapReduce et mieux ce sera pour les utilisateurs.
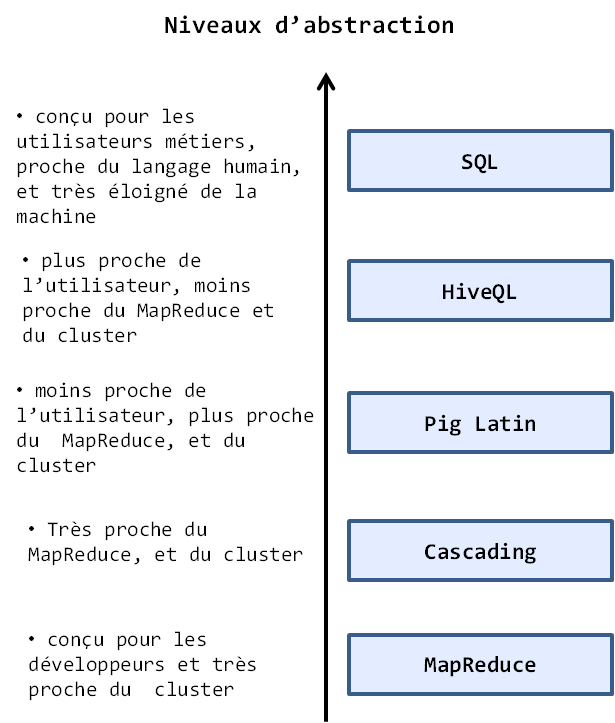
Attention, plus le niveau d'abstraction d'un langage est élevé et plus le niveau de complexité des requêtes qu'on peut y exprimer est faible. C'est pourquoi il est bénéfique que vous appreniez à la fois Hive et Pig.
Ainsi, si vous n'arrivez pas à exprimer votre problème sous forme de requêtes Hive, alors vous pourrez toujours utiliser Pig. Si vous voulez aller plus loin, vous pouvez aussi apprendre le Cascading.
II-A. Hive▲
Originalement développé par Facebook pour la gestion de son réseau social, Hive est une infrastructure informatique similaire au Data Warehouse qui fournit des services de requêtes et d'agrégation de très gros volumes de données stockées sur un système de fichier distribué de type HDFS. Il a été originalement conçu par Facebook qui cherchait à fournir à ses analystes de données (des non-développeurs) une infrastructure informatique et un langage proche du SQL pour l'exploitation de ses pétaoctets de données. Ainsi, Hive a été conçu pour un public qui possède de très bonnes compétences en SQL et des compétences relativement faibles en programmation Java.
II-A-1. Infrastructure technique de Hive▲
Hive fournit un langage de requête basé sur le SQL (norme ANSI-92) appelé HiveQL (Hive Query Language), qui est utilisé pour adresser des requêtes aux données stockées sur le HDFS. Le HiveQL permet également aux utilisateurs avancés/développeurs d'intégrer des fonctions Map et Reduce directement à leurs requêtes pour couvrir une plus large palette de problèmes de gestion de données. Cette capacité de plug-in du MapReduce sur le HiveQL s'appelle les UDF (User Defined Function). La figure suivante illustre l'architecture de Hive.

En fait, lorsque vous écrivez une requête en HiveQL, cette requête est transformée en job MapReduce et soumise au JobTracker pour exécution par Hive. Étant donné que les données de la requête ne sont pas stockées dans une table comme dans le cas d'une requête SQL classique, Hive s'appuie sur une couche de stockage de données installée sur Hadoop à l'exemple d'HCatalog, pas pour le stockage des données du HDFS, mais pour le stockage des métadonnées des requêtes des utilisateurs. Notez qu'une couche logicielle de stockage autre que HCatalog peut être utilisée. L'utilisateur commence sa requête en définissant la ou les tables HCatalog qu'il veut manipuler, si elle(s) n'existe(nt) pas, il l(es) crée(nt) dans HCatalog, ensuite définit leurs colonnes et les opérations à effectuer pour obtenir ces colonnes. Une fois qu'il soumet sa requête, cette dernière est transformée en jobs MapReduce. Il est important de comprendre que les tables HCatalog ne stockent pas les données, elles font juste référence de pointeurs aux données qui sont sur le HDFS. Étant donné que le HCatalog est indépendant du HDFS et du Hive, il peut être utilisé comme intermédiaire de connexion aux données contenues dans les systèmes de Business Intelligence de l'entreprise. C'est le but de la présence des connecteurs ODBC/JDBC dans l'infrastructure Hive. Pour l'intégration directe des fonctions Map et Reduce sous forme d'UDF (User Defined Functions) dans la requête HiveQL, HIVE s'appuie sur Apache Thrift qui lui permet entre autres d'écrire les UDF en plusieurs langages de programmation (Java, Python, Ruby…).
II-A-2. Écriture des requêtes HiveQL▲
Nous allons maintenant entrer concrètement dans l'écriture des requêtes HiveQL. Lorsque vous voulez écrire des requêtes HiveQL, voici en général l'ensemble des étapes que vous devez respecter. Nous allons illustrer ces étapes à l'aide d'un exemple. Considérons le fichier suivant :
|
id_client |
Nom_client |
Prenom_client |
date_naissance |
Genre |
Produit_achete |
Quantite |
Prix_unitaire |
|---|---|---|---|---|---|---|---|
|
1 |
DELATABLE |
Jean |
10/08/1987 |
Masculin |
détergent |
2 |
10 euros |
|
2 |
CHOKOGOUE |
Juvénal |
11/10/1982 |
Masculin |
costume |
1 |
400 euros |
|
3 |
MORANO |
princesse |
12/08/1990 |
Féminin |
véhicule |
1 |
10000 euros |
|
4 |
GUIGALE |
julien |
03/08/1989 |
Masculin |
dentifrice |
4 |
13 euros |
|
5 |
MUNROE |
léon |
07/07/1986 |
Masculin |
livre |
10 |
14 euros |
|
6 |
DUPONT |
anae |
12/08/1990 |
Féminin |
véhicule |
1 |
7000 euros |
|
7 |
MAGDALA |
marie |
16/02/1987 |
Féminin |
tablette |
1 |
77 euros |
|
8 |
BODOURT |
christophe |
25/04/1990 |
Masculin |
maison |
1 |
125800 euros |
|
9 |
LEMARCHANE |
josué |
18/03/1983 |
Masculin |
véhicule |
1 |
5900 euros |
|
10 |
KRAG |
foster |
30/06/1989 |
Masculin |
véhicule |
1 |
8500 euros |
|
11 |
BIZ |
anicet |
20/01/1988 |
Masculin |
détergent |
2 |
20 euros |
|
12 |
BIZOT |
david |
21/08/1987 |
Masculin |
véhicule |
1 |
12000 euros |
|
13 |
LACROIX |
sylvestre |
22/08/1987 |
Masculin |
livre |
2 |
22 euros |
- La première étape dans l'écriture de la requête consiste à définir la base de données dans laquelle sera stockée la table de référence dans le catalogue, HCatalog. HCatalog possède une base « default » qui est utilisée par défaut pour le stockage des métadonnées. L'instruction suivante définit la base de données de catalogue :
USEdefault; -
La deuxième étape consiste à créer une table intermédiaire dans la base de catalogue. Cette table va pointer vers les données de tous les fichiers sources que vous voulez traiter. Pour ce faire, vous utiliserez une instruction
CREATETABLE.Sélectionnez1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.CREATETABLEIFNOTEXISTSlog_clients(id_clientSTRING, Nom_clientSTRING, prenom_clientSTRING, Noms_clientSTRING, date_naissanceDATE, genreSTRING, produit_acheteSTRING, QantitéTINYINT, Prix_unitaireSTRING)ROWFORMATDELIMITEDFIELDSTERMINATEDBY'\t',STOREDASTEXTFILE;Dans le cas de notre exemple, cette instruction crée une table log_clients contenant toutes les colonnes du fichier source. L'instruction
ROWFORMATDELIMITEDFIELDSTERMINATEDBYpermet de préciser le code ANSI du séparateur de colonnes (la tabulation dans notre cas) dans le fichier source, et l'instructionSTOREDASpermet de spécifier le format sur lequel le fichier est sérialisé dans le HDFS (ici c'est un fichier plat classique). -
La troisième étape consiste à charger les données du HDFS dans la table intermédiaire. Le chargement de données du HDFS se fait à l'aide de l'instruction
LOADDATA.Sélectionnez1.LOADDATAINPATH'/user/projetdemo/clients'OVERWRITEINTOTABLElog_clients ;Le chemin '/user/projetdemo/clients' spécifie le chemin d'accès sur le HDFS du dossier contenant le ou les fichiers dont les données seront analysées. Le mot clé OVERWRITE permet d'écraser les données éventuelles qui pourraient être déjà présentes dans la table lors du stockage des nouvelles données.
-
La quatrième étape consiste à construire la table dont vous avez besoin pour vos analyses. Cette fois, vous devez spécifier à partir de la table intermédiaire les calculs nécessaires pour obtenir les colonnes dont vous avez besoin. Supposons dans notre exemple que nous voulons les colonnes suivantes :
- la colonne « Noms du client », obtenue par concaténation des colonnes « nom_client » et « prenom_client » ;
- la colonne « Sexe », obtenue par l'extraction de la première lettre de la colonne « genre » ;
- la colonne « age_client », obtenue par différentiel de date entre la colonne « date_naissance » et la date d'aujourd'hui ;
- la colonne « vente », obtenue par multiplication des colonnes « prix » et « quantité » ;
2.
3.
4.
5.
6.
7.
8.
CREATE TABLE IF NOT EXISTS Clients AS
SELECT
id_client STRING,
concat (Nom_client,' ', prenom_client) Noms_client
datediff (date_naissance, CURRENT_DATE()) Age_client,
Substr (genre, 1, 1) genre,
Qantité * Prix_unitaire Vente
FROM log_clients ;
- la dernière étape enfin, consiste à effectuer vos analyses sur la table que vous venez de créer. Pour ce faire, vous utiliserez une instruction
SELECTclassique. Supposons que dans notre exemple, nous souhaitons obtenir la somme des ventes par genre des clients qui ont entre 25 et 30 ans. Nous obtiendrons la requête suivante :
SELECT sum (vente) FROM Clients WHERE cast (age_client as int) BETWEEN 25 AND 30 GROUP BY genre ;
L'ensemble du programme Hive qui résout notre problème est le suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
USE default ;
CREATE TABLE IF NOT EXISTS log_clients(
id_client STRING,
Nom_client STRING,
prenom_client STRING,
Noms_client STRING,
date_naissance DATE,
genre STRING,
produit_achete STRING,
Qantité TINYINT,
Prix_unitaire STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t',
STORED AS TEXTFILE;
LOAD DATA INPATH '/user/projetdemo/clients' OVERWRITE INTO TABLE log_clients ;
CREATE TABLE IF NOT EXISTS Clients AS
SELECT
id_client STRING,
concat(Nom_client,' ', prenom_client) Noms_client
datediff(date_naissance, CURRENT_DATE()) Age_client,
Substr(genre, 1, 1) genre,
Qantité * Prix_unitaire Vente
FROM log_clients ;
SELECT sum(vente) FROM Clients WHERE cast(age_client as int) BETWEEN 25 AND 30 GROUP BY genre ;
Comme vous pouvez le voir, il est relativement simple d'exprimer ses requêtes en HiveQL. L'utilisateur métier se retrouve alors en train d'exploiter tout un cluster et de faire du MapReduce sans en faire !
Comme nous vous l'avons signalé plutôt, le problème avec les langages de haut niveau d'abstraction comme HiveQL est qu'ils sont trop descriptifs, ils permettent d'exprimer ce qu'il faut faire, sans permettre d'exprimer comment faire ce qu'il faut faire. Ce qui pose problème dans la mesure où tous les problèmes ne peuvent pas toujours s'exprimer de façon descriptive. Il est alors nécessaire de réduire le niveau d'abstraction, pas trop tout de même, pour éviter de décourager l'utilisateur chevronné. C'est le but de Pig.
II-B. Pig ▲
Il a été réalisé que le potentiel d'Hadoop ne pouvait pas être déployé si les opérations courantes nécessitaient toujours les développeurs Java hautement qualifiés pour leur programmation. Comme nous l'avons vu précédemment, la réponse à cette solution chez Facebook a été le développement de Hive. Chez Yahoo !, l'équipe d'ingénieurs Hadoop a eu l'impression qu'une solution basée sur le SQL ne pouvait pas suffisamment couvrir la complexité de la programmation de certaines tâches MapReduce. Par voie de conséquence, Yahoo ! a créé un langage qui maximise la productivité des analystes de données (un public non-développeur), tout en offrant le support nécessaire pour l'expression des opérations MapReduce complexes. Cette solution c'est Pig.
Pig est un environnement d'exécution de flux interactifs de données sous Hadoop. Il est composé de deux éléments :
- un langage d'expression de flux de données appelé le Pig Latin ;
- et un environnement interactif d'exécution de ces flux de données.
Le langage offert par Pig, le Pig Latin, est à peu près similaire au langage de Scripting tels que Perl, Python, ou Ruby. Cependant, il est plus spécifique que ces derniers et se décrit mieux sur le terme « langage de flux de données » (data flow language). Il permet d'écrire des requêtes sous forme de flux séquentiels de données sous Hadoop à la façon d'un ETL (Extract, Transform and Load). Ces flux sont ensuite transformés en fonctions MapReduce qui sont enfin soumises au jobtracker pour exécution. Pour faire simple, Pig c'est l'ETL d'Hadoop. Programmer en Pig Latin revient à décrire sous forme de flux indépendants, mais imbriqués, la façon dont les données sont chargées, transformées, et agrégées à l'aide d'instructions Pig spécifiques appelées opérateurs. La maîtrise de ces opérateurs est la clé de la maîtrise de la programmation en Pig Latin, d'autant plus qu'ils ne sont pas nombreux relativement au Hive par exemple. Le tableau suivant récapitule les opérateurs usuels de Pig.
Tableau 1 : liste des opérateurs usuels de Pig Latin
|
Catégorie |
Opérateur |
Description |
|---|---|---|
|
Chargement et stockage |
LOAD |
charge les données du HDFS ou d'une autre source |
|
STORE |
persiste les données dans le HDFS ou dans un autre système destinataire |
|
|
DUMP |
effectue un 'print' classique (affiche les résultats des traitements sur l'écran) |
|
|
Filtrages |
FILTER |
filtre les données selon les critères définis par l'utilisateur |
|
DISTINCT |
supprime les doublons |
|
|
FOREACH…GENERATE |
ajoute ou supprime les champs dans le fichier de données |
|
|
SAMPLE |
sélectionne un échantillon dans le fichier de données |
|
|
Agrégation |
JOIN |
jointure de deux ou plusieurs fichiers de données |
|
GROUP |
Groupe les données en un seul fichier |
|
|
CROSS |
crée un tableau croisé de deux ou plusieurs fichiers de données |
|
|
UNION |
combine verticalement deux ou plusieurs fichiers de données en un seul |
|
|
Tri |
ORDER |
tri les données selon un ou plusieurs champs |
Tout comme Hive, Pig offre la possibilité d'intégrer des UDF à ses scripts pour la résolution des problèmes plus complexes à exprimer sous forme de flux. De plus, la latence qui est occasionnée avec Hive est également présente avec l'utilisation de Pig. Revenons sur l'exemple que nous avons utilisé précédemment dans Hive. Le même problème écrit en Pig Latin donne ceci :
-
La première étape consiste à charger les données de la source (ici le HDFS) en utilisant l'opérateur de chargement de données
LOAD. La fonction PigStorage() vous permet de préciser le format de fichier des données source. Si vos données sont structurées alors vous utiliserez l'instruction PigStorage() en précisant le séparateur de colonne, si vos données sont non structurées, vous utiliserez la fonction TextLoader(), si les données sont binaires ou compressées, alors vous utiliserez BinStorage() et si les données sont de type JSON vous utiliserez JSONStorage(). Les fonctions d'intégration de nouveaux formats de données sont constamment développées par la fondation Apache.Sélectionnez1.log_clients=LOAD'/user/projetdemo/clients/'USINGPigStorage('\t')AS(id_client:int, Nom_client : chararray, Prenom_client :chararray, date_naissance :datetime, Genre: chararray, Produit_achete : chararray, Qantite:int, Prix_unitaire:float); -
À la deuxième étape, les colonnes sont calculées à l'aide de l'opérateur
FOREACHet calculées presque de la même façon qu'avec Hive.Sélectionnez1.Clients=FOREACHlog_clients GENERATE id_client,concat(Nom_client,' ', prenom_client)ASNoms_client, YearsBetween(date_naissance,CURRENT_TIME())ASAge_client,Substr(genre,1,1)ASSexe_client, Qantité*Prix_unitaireASVente; - La requête
SELECTde Hive est décomposée ici en trois flux distincts : le filtre, le groupement et le calcul de la somme.
2.
3.
4.
clients25_30 = FILTER Clients BY (Clients >= 25 AND Clients <= 30);
clients25_30_groupes = GROUP clients25_30 BY genre;
Ventes = FOR EACH clients25_30_groupes GENERATE genre, sum(vente) ;
DUMP Ventes;
La requête complète est la suivante :
2.
3.
4.
5.
6.
log_clients = LOAD '/user/projetdemo/clients/' USING PigStorage ('\t') AS (id_client: int, Nom_client : chararray, Prenom_client :chararray, date_naissance : datetime, Genre: chararray, Produit_achete : chararray, Qantite: int, Prix_unitaire: float);
Clients = FOR EACH log_clients GENERATE id_client, concat(Nom_client,' ', prenom_client) AS Noms_client, YearsBetween(date_naissance, CURRENT_TIME()) AS Age_client, Substr(genre, 1, 1) AS Sexe_client, Qantité * Prix_unitaire AS Vente;
clients25_30 = FILTER Clients BY (Clients >= 25 AND Clients <= 30);
clients25_30_groupes = GROUP clients25_30 BY genre;
Ventes = FOR EACH clients25_30_groupes GENERATE genre, sum(vente) ;
DUMP Ventes;
La figure suivante récapitule les changements qui se sont produits lors du passage de HiveQL à Pig Latin, les instructions Pig Latin et leurs équivalences en HiveQL. Cela vous permet de voir la différence entre les deux styles de programmation.
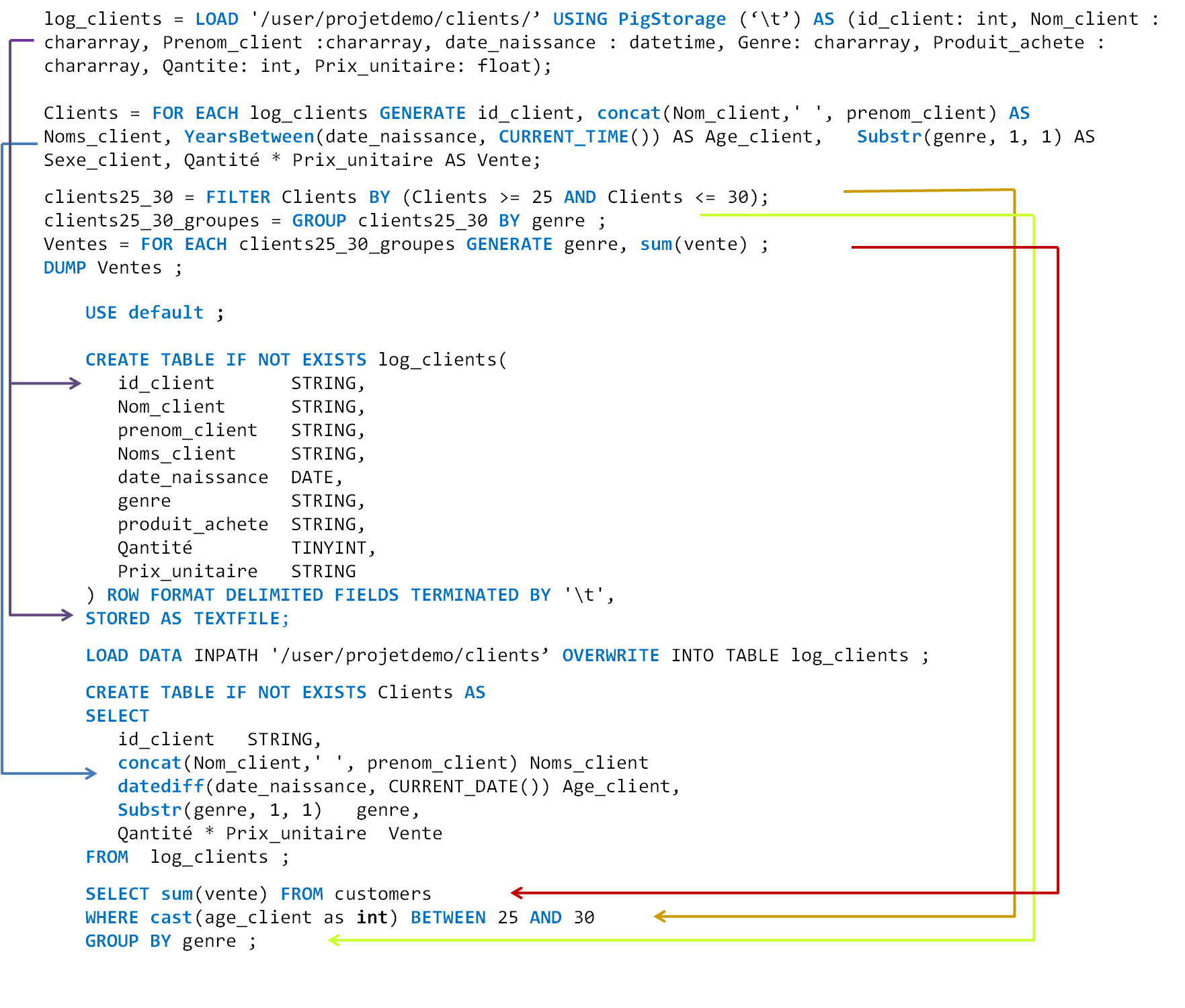
Nous allons conclure cette partie sur les langages d'abstractions disponibles sur Hadoop avec un petit mot sur la différence entre Hive et Pig. Tout d'abord, gardez à l'esprit que tous deux sont des langages d'abstraction, ils ont pour but d'éloigner le public non-développeur (les analystes métier) de la complexité de la programmation des tâches Map et Reduce dans un langage tel que Java. L'atteinte de ce but a pour inconvénient de prolonger le temps de latence de l'exécution des jobs MapReduce qui en résultent, que ça soit aussi bien pour Hive que pour Pig. C'est à cause de cela que la fondation Apache a développé un autre langage d'abstraction, mais cette fois-ci très proche du MapReduce appelé Cascading
II-C. Cascading▲
Cascading offre un style de programmation très similaire à Pig Latin, mais en Java. Vous vous doutez bien que Cascading n'est presque pas utilisé par le public qu'il ciblait originellement (les analystes métier). Malgré l'avantage et inconvénient commun à Hive et Pig, il existe tout de même une différence fondamentale qui peut faire pencher la balance envers l'un ou l'autre. Le Pig Latin est un langage dans lequel l'utilisateur décrit le COMMENT des opérations à réaliser, tandis que HiveQL décrit simplement le QUOI et laisse le soin au système de faire le reste. À cause de ce mode de fonctionnement, Pig est plus complexe à programmer que HiveQL, ce qui fait que sa courbe d'apprentissage est globalement plus élevée que celle de Hive. Par contre, Pig Latin permet de couvrir une plus large palette d'opérations que le Hive. Donc, lorsque la question du choix se posera entre les deux, tenez en compte le niveau technique des utilisateurs (surtout leur niveau de programmation en SQL) et du niveau de complexité des opérations à réaliser. À défaut d'utiliser un langage d'abstraction, il est possible d'utiliser le SQL directement sur Hadoop, ceci est une nouvelle qui devrait réjouir tout analyste métier et qui fera l'objet de notre prochain article.
Depuis la version 2 d'Hadoop, Hive et Pig s'appuient désormais sur TEZ et plus sur le MapReduce. Les requêtes HiveQL e Pig Latin sont transformées en plan d'exécution TEZ (Graphes acycliques Direct les plus courts possibles), ce qui réduit considérablement leur latence.
III. Note de la rédaction developpez.com ▲
Ce cours est un extrait du livre intitulé Hadoop : Devenez opérationnel dans le monde du Big Data.
La rédaction de développez.com tient à remercier Juvénal CHOKOGOUE qui nous a autorisés à publier ce cours.
Nous remercions également Jacques_jean pour la relecture orthographique.