



I. Introduction▲
La mise en œuvre d’un cluster Hadoop demande des coûts financiers importants. L’économie numérique, grâce à la baisse des coûts des infrastructures informatiques qui la caractérise, a permis l’émergence d’un nouveau type de modèle économique : le Cloud Computing. Aujourd’hui, grâce au Cloud, les entreprises ont l’opportunité de rendre variables les dépenses de leur infrastructure informatique. En effet, certaines entreprises ont réussi à profiter de la baisse des coûts informatiques, de l’accroissement de la bande passante et du développement des technologies Internet, pour proposer la mise à disposition de leurs ressources informatiques (ordinateurs, puissance de calcul, RAM, logiciels, disques durs, etc.) à d’autres entreprises, sur une base de paiement à l’usage. Ces sociétés s’appellent les fournisseurs Cloud. Grâce à leur offre, les entreprises peuvent désormais louer les logiciels et les ressources informatiques dont elles ont besoin pour réaliser leurs expérimentations, sans se soucier de la maintenance de celles-ci. Certains fournisseurs Cloud sont allés plus loin encore et ont réussi à proposer Hadoop en Cloud, sous forme de service payé à l’usage. Ce positionnement supprime la barrière à l’entrée que représentaient l’acquisition et la maintenance d’un cluster Hadoop et donne à toutes les entreprises, indépendamment de leur taille ou leur budget, la possibilité de louer un cluster Hadoop sans s’encombrer des charges de maintenance. Dans ce tutoriel, qui est plus stratégique que pratique, nous allons vous montrer comment exploiter Hadoop dans le Cloud. Dans un premier temps, nous allons définir en termes très simples la notion de Cloud Computing, ensuite, nous vous aiderons à faire le lien entre le Cloud et Hadoop et enfin, nous analyserons dans le détail les deux solutions Cloud majeures d’Hadoop sur le marché : Amazon, avec son offre Amazon EMR et Microsoft, avec son offre Azure HDInsights.
Attention ! n’interprétez pas le choix d’EMR et d’Azure comme de la publicité ou une indication de supériorité comparativement à d’autres offres du marché. Notre but est de compléter votre connaissance du fonctionnement d’Hadoop dans le Cloud et de vous faire comprendre la façon dont Hadoop est facturé en Cloud. Ces offres sont utilisées à titre illustratif. Aussi, les tarifs et la composition de ces offres évoluent beaucoup. Pour plus de précisions, renseignez-vous directement sur leur site Internet.
II. Définition du Cloud Computing▲
Les serveurs dans les entreprises tournent rarement à pleine puissance de leur capacité pendant toute leur durée de vie. La baisse des coûts des ordinateurs, combinée à la rapidité de la bande passante a permis à certaines entreprises qui possèdent d’immenses Data center de vendre le supplément de ressources informatiques de leurs Data Centers ; cette idée a donné naissance à un modèle économique qui est appelé le Cloud Computing ou Cloud tout simplement. Dans ce point, nous allons couvrir tous les aspects qui entrent dans la définition du Cloud. Le Cloud Computing se définit selon deux aspects : un aspect économique et un aspect technique.
II-A. Définition économique du Cloud Computing▲
Économiquement parlant, le Cloud Computing est un modèle dans lequel une entreprise (fournisseur Cloud) offre comme produit un service Cloud via Internet. Les services Cloud sont des ressources informatiques pouvant représenter les ressources RAM, la puissance de Microprocesseur, la bande passante, un logiciel, une interface applicative, un environnement de développement ou des clusters entiers d’ordinateurs. Ces services Cloud sont offerts sous forme de services Web, leur accès est contrôlé par une API et leur exploitation fait l’objet d’une facturation en fonction du volume de ressources utilisées, par exemple le nombre de requêtes HTTPS adressées à l’API par minute, la puissance de calcul consommée par heure, la quantité de mémoire utilisée par semaine, etc. À partir de cette configuration, les fournisseurs Cloud définissent des offres Cloud qui correspondent à des tarifications d’accès à des quantités précises de ressources dans un intervalle de temps, par exemple accès à 10 Go de disque dur à 4 euros/mois, accès à 1 ordinateur de 40Go de disque, 1 GHz Intel Dual Core de microprocesseur et 4 Go de RAM à 5 euros de l’heure. L’entreprise cliente sélectionne et s’abonne à l’offre Cloud qui correspond à ses besoins et paye à l’usage (c’est ce qu’on appelle en économie une structure de coût « Pay-As-You-Go »). Elle peut se désabonner à tout moment, payant ainsi uniquement les ressources qu’elle a consommées. Donc, économiquement parlant, le Cloud Computing est une forme de leasing (location) dans laquelle ce sont les ressources informatiques qui sont louées.
II-B. Définition technique du Cloud Computing▲
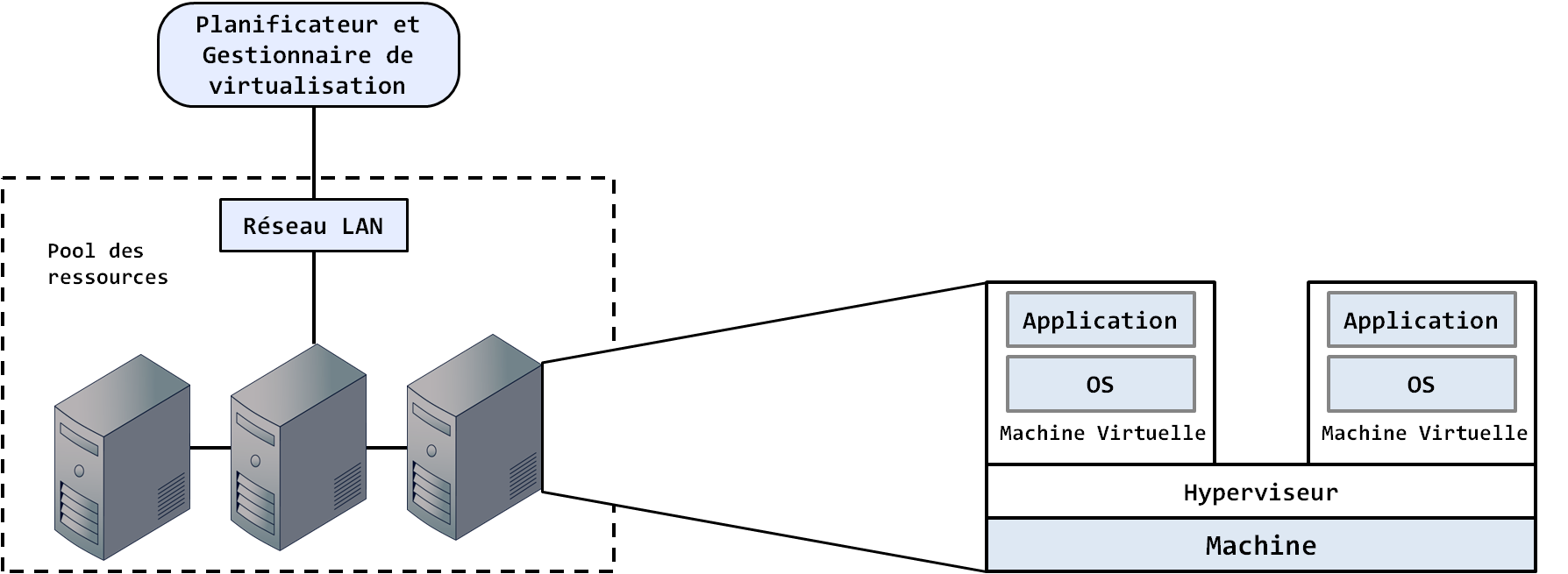
Techniquement parlant, le Cloud Computing c’est de la virtualisation informatique. La virtualisation fait référence à l’abstraction physique des ressources informatiques. En d’autres termes, les ressources physiques d’une machine (puissance de calcul, mémoire, disque dur, réseau) sont allouées à ce que l’on appelle une « machine virtuelle », c’est-à-dire une application logicielle qui est l’abstraction des ressources de la machine hôte (ou machine sur laquelle est démarrée cette machine virtuelle). La machine hôte voit cette machine virtuelle comme une application à laquelle elle distribue ses ressources. Les machines virtuelles sont construites à partir de l’excès des ressources de la machine hôte et sont gérées par un hyperviseur. L’hyperviseur gère les ordinateurs et les serveurs d’un système informatique comme un ensemble de pools auxquels il affecte dynamiquement les ressources en fonction des besoins des requêtes des utilisateurs du système. La figure suivante illustre globalement le processus de virtualisation.
 |
|
Figure 1 : le processus de virtualisation. Un gestionnaire de virtualisation constitue un pool de ressources de toutes les machines du réseau, l’hyperviseur, installé au niveau de chaque machine, crée les machines virtuelles et les provisionne à partir de l’excédent des ressources de la machine (dans la figure, les provisions allouées aux machines virtuelles sont représentées par la couleur identique à celle de la machine). |
La virtualisation a permis d'optimiser l'usage des ressources matérielles en les partageant simultanément entre plusieurs utilisateurs, ce qui était impossible auparavant puisque chaque machine correspondait obligatoirement à une machine physique identifiée et réservée à un usage exclusif. La virtualisation s'est combinée avec l'augmentation de la bande passante et la diminution des coûts des ordinateurs, suivant la tendance confirmée sur plusieurs décennies par Gordon Moore. Le déploiement de ce nouveau modèle d'accès aux serveurs s'est produit en même temps qu'apparaissait un nouveau mode de facturation des solutions logicielles, dans lequel le paiement annuel de licences d'utilisation d'un logiciel déployé sur les machines du client a été remplacé par un paiement à l'usage d'un logiciel centralisé, opéré directement par son éditeur. C’est ainsi que le Cloud Computing tel qu’on le connaît aujourd’hui est né. La virtualisation va largement bien au-delà de ce que nous vous avons exposé ici. Pour plus de détails, n’hésitez pas à consulter le chapitre 17 de notre ouvrage « ![]() Maîtrisez l’utilisation des technologies Hadoop – Initiation à l’écosystème Hadoop », paru chez les éditions Eyrolles.
Maîtrisez l’utilisation des technologies Hadoop – Initiation à l’écosystème Hadoop », paru chez les éditions Eyrolles.
II-C. Taxonomie des services Cloud▲
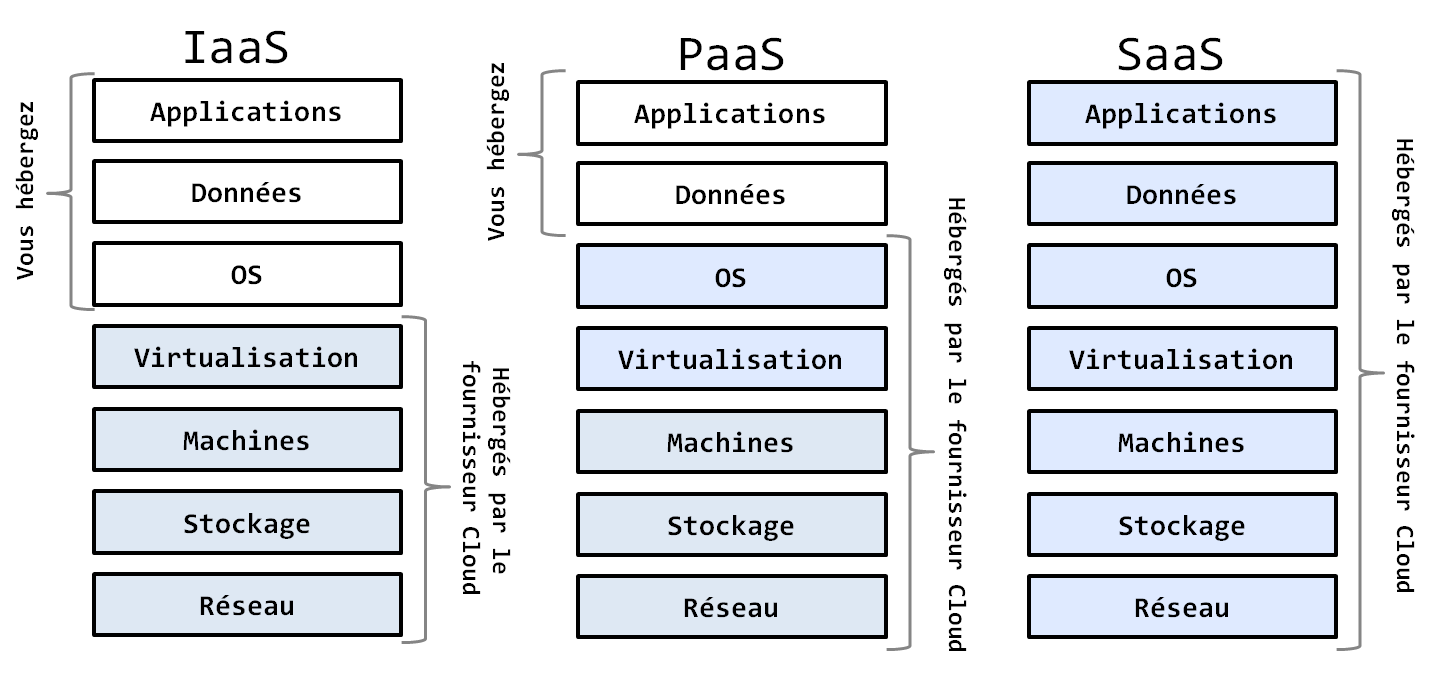
Les services Cloud représentent les ressources informatiques offertes. Les offres des éditeurs cloud dépendent du type de ressources offert. En fonction de ces types, on distingue 3 catégories d’offres commerciales Cloud (ou taxonomie cloud) : l’IaaS, le PaaS et le SaaS.
- IaaS ou Infrastructure-as-a-Service : est un niveau de service qui permet à des entreprises de louer des centres de données (data Centers), serveurs, réseaux, bref, de s’équiper d’un système informatique complet sans s’inquiéter de créer et de maintenir la même infrastructure en interne ;
- PaaS ou Platform-as-a-Service : est un niveau de service du Cloud dans lequel le fournisseur héberge et fournit un environnement de développement intégré (EDI) qu’un développeur peut utiliser pour créer et développer des logiciels, éliminant de ce fait la nécessité pour l’entreprise d’acheter constamment des EDI ;
- SaaS ou Software-as-a-Service : est un niveau de service du Cloud dans lequel le fournisseur héberge et met à disposition un logiciel ou une application, sans que l’entreprise n’ait à se soucier de l’installation et de la maintenance de cette application en interne ;
L’image ci-dessous va vous permettre de comprendre clairement la taxonomie des services offerts en Cloud Computing et les niveaux de responsabilités partagées entre le fournisseur Cloud et le client à chaque type de service.
 |
|
Figure 2 : taxonomie des services Cloud. Les rectangles colorés correspondent aux ressources informatiques qui sont hébergées et maintenues par le fournisseur Cloud, tandis que ceux qui sont non-colorés correspondent aux ressources informatiques que l’entreprise cliente héberge et maintient chez elle. |
Le Cloud a permis aux éditeurs logiciels de revoir leur modèle économique pour l’aligner aux exigences de la nouvelle économie. Il leur a permet de transformer leurs applications du livrable Standalone en services Web mis à disposition de leurs utilisateurs au travers de terminaux connectés à Internet, selon la taxonomie évoquée ci-dessus (IaaS, PaaS ou SaaS). À ce stade de lecture, vous avez la connaissance nécessaire sur le Cloud Computing pour comprendre comment Hadoop y est utilisé.
III. Utilisation d’Hadoop dans le Cloud : HaaS ou IaaS ?▲
Lorsqu’Hadoop est offert en Cloud, il peut être décliné en deux options, soit sous forme d’IaaS (Infrastructure as Service) préconfiguré, soit sous forme d’Hadoop as a Service.
III-A. IaaS préconfiguré ▲
Dans cette option, le fournisseur Cloud vous offre des instances préconfigurées de machines virtuelles avec une image de distribution Hadoop prépackagée à déployer sur ces instances. Chaque instance correspond à une configuration précise de machines virtuelles. Par exemple, un fournisseur peut offrir 2 instances I1 et I2, où I1 correspond à des machines virtuelles de processeur Intel Xeon® E5-2686 v4 dual core cadencé à 2,3 GHz, 8 Go de mémoire RAM et 450 Mo/s de bande passante ; et I2 correspond à des machines virtuelles de processeur Intel Xeon® E5-2680 v2 quadri core cadencé à 1,3 GHz, 8 Go de mémoire RAM et 1 Go/s de bande passante. Vous sélectionnez simplement l’instance des machines virtuelles qui convient à vos besoins, le nombre d’instances et vous déployez l’image de la distribution proposée par le fournisseur. Ou alors, en fonction des caractéristiques des machines que vous voulez pour votre cluster (caractéristiques des nœuds de données et du nœud de référence, débit de la bande passante dans le cluster, sécurité, accès réseau, etc.), vous créez vous-même les machines virtuelles sur l’environnement virtuel du fournisseur, l’organisez en cluster et y déployez la distribution Hadoop prépackagée. La distribution Hadoop prépackagée inclut un système d’exploitation (là encore au choix) et les outils de l’écosystème de la distribution. Dans cette option, la facturation est faite uniquement sur les ressources informatiques que vous consommez sur une période, comme les instances de machine virtuelle utilisées par heure, la puissance de calcul utilisée par heure ou le volume de données traité par heure. L’offre Amazon Elastic Cloud Compute (Amazon EC2) est un exemple d’offre IaaS préconfigurée.
III-B. Hadoop as a Service ▲
Comme son nom l’indique, dans cette option, Hadoop est offert comme un service Web. Là où dans l’option IaaS préconfiguré ce sont juste les instances de machines virtuelles qui sont facturées, dans l’option Hadoop as a Service , ce sont des instances de service Hadoop qui sont facturées. Une instance de service Hadoop est la combinaison d’une instance et d’une distribution Hadoop ou des composants spécifiques d’Hadoop directement installés sur ces instances. Par exemple, le client peut acheter des instances Spark, qui correspondent à des instances de machines virtuelles avec des configurations précises sur lesquelles sont installées Spark, des instances Storm, des instances HBase, etc. Ces instances sont automatiquement organisées en cluster complet (Nœuds de données et nœud de référence), scalable et tolérant aux pannes par le fournisseur Cloud, ce qui vous évite de vous préoccuper de la mise en place et de la mise en service du cluster et d’Hadoop vous-même. Ce cluster peut s’approvisionner automatiquement en ressources si la charge de travail venait à dépasser la capacité de calcul du cluster, ce qui n’est pas le cas dans l’option précédente où il faudrait arrêter le cluster, acheter des instances de plus grande taille, redimensionner manuellement le cluster et le relancer. En fait, l’option IaaS préconfigurée est recommandée principalement si vous voulez être chez un fournisseur IaaS bien précis (à cause des contraintes réglementaires liées à la localisation des données par exemple) ou si vous voulez tester des versions très récentes (ou version bêta) d’Hadoop ou de son écosystème. En dehors de ces deux cas d’utilisation, c’est l’option Hadoop as a Service qui est recommandée pour l’utilisation d’Hadoop dans le Cloud.
La facturation des offres de stockage fait l’objet d’une tarification séparée. Par défaut, que ce soit avec l’option Hadoop as a Service ou IaaS préconfiguré, l’utilisation des instances se fait sans persistance des données et celles-ci (les données) sont supprimées après le traitement. Voici le schéma de fonctionnement : lorsque vous exécutez un traitement, les données sont chargées du local (c’est-à-dire de vos environnements) ou d’un service de stockage Cloud (appelé techniquement un Object Store) vers un Object Store, ensuite, les machines virtuelles des nœuds de données sont instanciées et provisionnées conformément à la configuration à laquelle le client a souscrit, les traitements sont réalisés par ces machines en lisant les données depuis l’Object Store dans lequel les données sont stockées. À la fin du traitement, si vous avez souscrit au service Cloud de stockage (par exemple Amazon S3 ou Microsoft Azure Blob Storage), le résultat est renvoyé dans cet Object Store et les machines sont supprimées, sinon, les résultats et les données sont supprimés à la déconnexion du service.
III-C. Différence entre IaaS et HaaS▲
Ce tableau comparatif va vous aider à mieux cerner les différences entre l’IaaS préconfiguré, le Hadoop as a Service et la configuration qui peut correspondre à vos besoins ou à ceux de vos clients.
|
IaaS préconfiguré |
Hadoop as a Service |
|
|
Offre Cloud |
Instance de machines virtuelles à part + distribution/composant Hadoop à part + Object Store (optionnel). |
Instance de machines virtuelles à part + distribution/composant Hadoop + Object Store (optionnel) en un. |
|
Ressources Cloud |
Instances de taille fixe. Si la charge de calcul augmente, il faut arrêter le service, acheter des instances plus grandes, redimensionner le cluster et relancer le service. |
Instances de taille fixe au départ, mais qui se provisionnent automatiquement en cas de montée en charge et ce sans arrêt du service. Redimensionnement automatique. |
|
Facturation |
Ressources des instances utilisées par période + volume de stockage souscrit (cas où il y’a eu souscription à un Object Store). |
Ressources des instances utilisées par période + composant Hadoop souscrit + volume de stockage souscrit (cas où il y’a eu souscription à un Object Store) ou Volume de Débit de données transférées (cas où il n’y’a pas eu souscription à un Object Store). |
|
Indications |
Recommandé si :
|
Recommandé si :
|
|
Tableau 1: comparaison entre l'IaaS préconfiguré et le Hadoop as a Service |
Maintenant que vous savez comment Hadoop fonctionne dans le Cloud, nous allons passer en revue les deux offres Cloud Hadoop les plus influentes du marché : Amazon Elastic MapReduce (EMR) d’Amazon et Azure HDInsight de Microsoft. Notez que nous les avons choisies exclusivement sur la base de leur leadership sur le marché et sur la base de l’expérience personnelle que nous avons des deux sociétés. Ainsi, n’interprétez pas le choix de leur offre comme une indication de supériorité à d’autres offres du marché. Notre but est de compléter votre compréhension du fonctionnement d’Hadoop dans le Cloud et de vous faire comprendre la façon dont Hadoop est facturé en Cloud.
IV. Amazon Elastic MapReduce (EMR)▲
Amazon Elastic MapReduce ou simplement Amazon EMR est l’offre Cloud Hadoop d’Amazon. Elle offre aux entreprises et aux particuliers, la capacité de déployer en Cloud un ou plusieurs clusters sur lesquels est installée une distribution complète d’Hadoop avec son écosystème ou alors un composant de l’écosystème Hadoop. Le client a le choix entre la distribution MapR d’Hadoop, la distribution Hadoop personnalisée d’Amazon et depuis récemment, la distribution Hortonworks d’Hadoop. Amazon EMR n’est pas une offre tout-en-un, c’est une offre qui résulte de l’addition de plusieurs autres offres Cloud d’Amazon. En fait, EMR est juste la partie applicative du service. Vous choisissez séparément les instances de l’offre Amazon EC2 (Amazon Elastic Cloud Compute, l’offre IaaS d’Amazon) instances qui vont constituer votre cluster (standard, mémoire élevée, CPU élevée, etc.) et selon vos besoins, vous souscrivez à un abonnement Amazon S3 (Amazon Simple Storage Service, l’offre Cloud de stockage d’Amazon) pour la persistance des données que vous traitez dans le Cloud. Résumé en une équation, l’offre Hadoop dans le Cloud d’Amazon est la suivante :
Hadoop Cloud Amazon = instances Amazon EMR + instances Amazon EC2 + abonnement stockage Amazon S3
IV-A. Fonctionnalités d’Amazon EMR▲
L’offre Amazon EMR possède plusieurs caractéristiques qui la rendent intéressante pour l’utilisation d’Hadoop en Cloud. Nous allons présenter de façon succincte 3 d’entre elles. Vous trouverez l’exhaustivité de ces caractéristiques sur le site Web officiel d’Amazon dédié à AMR.
- redimensionnement automatique des clusters en cours d'exécution : Amazon EMR offre la possibilité de redimensionner un cluster en cours d'exécution. En d’autres termes, si la charge de calcul de vos traitements change, vous pouvez ajouter temporairement plus de puissance de traitement au cluster, ou bien réduire votre cluster pour diminuer les coûts. Par exemple, vous pouvez ajouter des centaines d'instances à vos clusters au moment du traitement par lots, puis supprimer les instances excédentaires lorsque celui-ci est terminé. Lorsque vous ajoutez des instances à votre cluster, EMR peut commencer à utiliser la capacité dimensionnée sans arrêter le cluster. Cet avantage rend l’offre scalable en termes de performances, flexible en termes de coûts et annule le besoin de planifier les pics ou creux de charge de calcul qui vont survenir dans le futur ;
- intégration avec des Services Cloud de stockage : vous pouvez utiliser Amazon EMR à partir des données stockées dans un service Cloud distinct (par exemple Amazon S3). Par exemple, supposons que vous stockez vos données chez un fournisseur Cloud particulier, vous pouvez utiliser des instances de cluster Amazon EMR pour vous connecter à ces données et les traiter. Ceci rend vos clusters et vos traitements indépendants de vos données. Cette caractéristique de l’offre a été rendue possible par le système de fichier EMRFS (Amazon EMR File System) mis au point par Amazon. Le système de fichiers EMR (EMRFS) permet aux clusters EMR d'utiliser par défaut Amazon S3 comme espace de stockage de données pour Hadoop. EMRFS offre des performances élevées en matière d'écriture vers et de lecture à partir d'Amazon S3, prend en charge le chiffrement S3 côté serveur ou côté client à l'aide d'AWS Key Management Service (KMS) ou de clefs gérées par le client et fournit une vue cohérente optionnelle, qui vérifie la liste et la cohérence read-after-write (lecture directe après écriture) des objets suivis dans ses métadonnées. De plus, les clusters EMR peuvent utiliser aussi bien le système EMRFS que le système HDFS ; vous n'avez donc pas à choisir entre un stockage sur le cluster et Amazon S3. Avec Amazon EMR, vous pouvez utiliser plusieurs Object Store, y compris Amazon S3, le système de fichiers distribués Hadoop (HDFS) et Amazon DynamoDB ;
- disponibilité d’une distribution complète d’Hadoop : Amazon EMR repose sur la distribution MapR d’Hadoop, en d’autres termes, tous les outils et technologies Hadoop disponibles dans la distribution MapR sont également disponibles en Cloud EMR. Il en est de même avec la disponibilité de la distribution Hortonworks HDP. Pour plus de détails concernant les composants Hadoop de MapR et de Hortonworks, veuillez vous référer à notre ouvrage, «
 Maîtrisez l’utilisation des technologies Hadoop – Initiation à l’écosystème Hadoophttps://www.data-transitionnumerique.com/ecosysteme-hadoop/» paru chez les éditions Eyrolles. En plus de ces deux distributions, Amazon met à disposition d’EMR sa propre distribution Hadoop, composée entre autres des outils tels qu’Amazon DynamoDB (un service de base de données NoSQL), Amazon Relational Database Service (un service Web qui facilite la configuration, l'exploitation et le dimensionnement des bases de données relationnelles dans le Cloud) et Amazon Redshift (un service d'entrepôt de données d'une capacité de plusieurs péta-octets). Amazon intègre également quelques outils Open source supplémentaires de l’écosystème Hadoop qui ne sont pas présents dans la distribution MapR, à savoir Apache Phoenix (permet d’exécuter les requêtes SQL sur les données stockées dans Apache HBase), Apache Flink (un moteur de streaming de données traitement temps réel), R, Mahout (environnement d’exécution des modèles d’apprentissage statistique selon le paradigme MapReduce), Ganglia (outil de monitoring du cluster Hadoop ) et Accumulo (un système de gestion de bases de données NoSQL initialement développé par la NSA avant d’être légué à la fondation Apache). Pour plus de détails sur l’ensemble des outils, veuillez consulter le site Web d’Amazon EMR.
Maîtrisez l’utilisation des technologies Hadoop – Initiation à l’écosystème Hadoophttps://www.data-transitionnumerique.com/ecosysteme-hadoop/» paru chez les éditions Eyrolles. En plus de ces deux distributions, Amazon met à disposition d’EMR sa propre distribution Hadoop, composée entre autres des outils tels qu’Amazon DynamoDB (un service de base de données NoSQL), Amazon Relational Database Service (un service Web qui facilite la configuration, l'exploitation et le dimensionnement des bases de données relationnelles dans le Cloud) et Amazon Redshift (un service d'entrepôt de données d'une capacité de plusieurs péta-octets). Amazon intègre également quelques outils Open source supplémentaires de l’écosystème Hadoop qui ne sont pas présents dans la distribution MapR, à savoir Apache Phoenix (permet d’exécuter les requêtes SQL sur les données stockées dans Apache HBase), Apache Flink (un moteur de streaming de données traitement temps réel), R, Mahout (environnement d’exécution des modèles d’apprentissage statistique selon le paradigme MapReduce), Ganglia (outil de monitoring du cluster Hadoop ) et Accumulo (un système de gestion de bases de données NoSQL initialement développé par la NSA avant d’être légué à la fondation Apache). Pour plus de détails sur l’ensemble des outils, veuillez consulter le site Web d’Amazon EMR.
Hortonworks a annoncé en fin 2016, la disponibilité de sa distribution Hadoop HDP sur le Cloud Amazon Web Service.
IV-B. Tarification d’Amazon EMR▲
Le modèle économique d'Amazon EMR consiste à facturer l'utilisation de chaque instance du cluster à l'heure. Par exemple, si vous souscrivez à un cluster de 10 nœuds pour 10 heures, le prix est identique à celui d’un cluster de 100 nœuds s'exécutant pendant une heure. 3 éléments principaux composent cette tarification : le type d'instance souscrit, l’édition de distribution MapR sélectionnée et la zone géographique souscrite.
- type d’instance : le premier critère consiste à déterminer les caractéristiques des instances qui vont former votre cluster. Pour cela, vous devez souscrire à des instances Amazon EC2. Amazon EC2 fournit un vaste éventail de types d’instances optimisés pour différents cas d’utilisation. Ces types d’instances correspondent à différentes combinaisons en termes de capacités de CPU, de mémoire, de stockage et de mise en réseau. Chaque type d’instance inclut une ou plusieurs tailles d’instances, ce qui vous permet de mettre à l’échelle vos ressources en fonction des exigences de la charge de travail prévue. Pour plus de détails sur les caractéristiques des différents types d’offres, veuillez consulter le site Web d’Amazon EC2. Le tableau suivant donne un aperçu des caractéristiques des types d’instances ;
|
Type d’instance |
Nombre de CPU |
Mémoire RAM Go |
Stockage (Go) |
Processeur physique |
Fréquence d’horloge (GHz) |
Tarif par heure en UE (Irlande) |
|
T2.nano |
1 |
0,5 |
En Object Store uniquement |
Série Intel Xeon |
Jusqu’à 3,3 |
$0.007 |
|
T2.large |
2 |
8 |
En Object Store uniquement |
Série Intel Xeon |
Jusqu’à 3,0 |
$0.112 |
|
M4.large |
4 |
16 |
En Object Store uniquement |
Intel Xeon E5-2676v3 |
2,4 |
$0.132 |
|
P2.8xlarge |
32 |
488 |
En Object Store uniquement |
Intel Xeon E5-2686v4 |
2,3 |
$7.776 |
|
i2.xlarge |
4 |
30,5 |
1 × 800 SSD |
Intel Xeon E5-2670v2 |
2,5 |
$0.938 |
|
Tableau 2 : tableau des caractéristiques des types d'instances Amazon EC2 avec pour système d’exploitation Linux. Les tarifs fournis sont les tarifs de l'instance en Union européenne (pour les serveurs Cloud d’Amazon situés en Irlande) |
Pour avoir les informations de tarification lorsque la distribution utilisée est HDP, veuillez vous rendre sur le site officiel de l’offre EMR d’Amazon.
- version de la distribution MapR sélectionnée : MapR décline sa distribution sur Amazon EMR en 3 distributions : l’édition M7, l’édition M5 et l’édition M3. Chaque édition correspond à un niveau de fonctionnalités couvert. Ci-après le tableau récapitulatif des fonctionnalités de chaque édition ;
|
Fonctionnalités MapR |
Edition M7 |
Edition M5 |
Edition M3 |
|
Distribution complète pour Apache Hadoop |
✓ |
✓ |
✓ |
|
Accès direct NFS |
✓ |
✓ |
✓ |
|
Évolutivité illimitée |
✓ |
✓ |
✓ |
|
Performances inégalées |
✓ |
✓ |
✓ |
|
MapR Control System (MCS) |
✓ |
✓ |
✓ |
|
Gestion de données basée sur les volumes |
✓ |
✓ |
|
|
Haute disponibilité non NameNode |
✓ |
✓ |
|
|
Haute disponibilité avec JobTracker HA |
✓ |
✓ |
|
|
Instantanés de fichiers |
✓ |
✓ |
|
|
Mise en miroir de fichiers |
✓ |
✓ |
|
|
Mises à niveau continues |
✓ |
✓ |
|
|
Récupération instantanée pour applications HBase |
✓ |
||
|
Aucune tâche d'administration HBase |
✓ |
||
|
Faible latence permanente pour HBase |
✓ |
||
|
Instantanés pour HBase |
✓ |
||
|
Mise en miroir pour HBase |
✓ |
|
Tableau 3 : tableau des fonctionnalités des éditions de MapR dans EMR |
- zone géographique : la tarification varie également en fonction de la zone géographique, c’est-à-dire de la zone où vos données sont hébergées. Amazon couvre 3 grandes zones : l’Amérique, l’Asie Pacifique et l’Union européenne (où elle a ses serveurs à Francfort et en Irlande) ;
Le tableau suivant donne un aperçu des grilles de tarif horaire d’Amazon EMR. Mais rapprochez-vous directement d’Amazon pour plus de précisions.
|
Type d’instance |
Tarif EC2 |
Tarif EMR |
|
m3.xlarge |
$0.293 par heure |
$0.070 par heure |
|
m1.medium |
$0.095 par heure |
$0.022 par heure |
|
r3.8xlarge |
$2.964 par heure |
$0.270 par heure |
|
i2.xlarge |
$0.938 par heure |
$0.213 par heure |
|
hs1.8xlarge |
$4.900 par heure |
$0.270 par heure |
|
Tableau 4 : tarifs des instances en Union européenne (Irlande) |
Attention ! les tarifs et la composition de l’offre complète d’Amazon sont en renouvellement permanent. Renseignez-vous directement auprès d’Amazon pour les informations à jour ou n’hésitez pas à vous rendre sur le site officiel de l’offre EMR d’Amazon.
V. Microsoft Azure HDInsight▲
On ne présente plus Microsoft, l’un des géants du monde logiciel. En matière de Cloud, Microsoft propose Azure. Azure couvre toutes les offres Cloud de Microsoft. L’Offre Cloud Hadoop est Azure HDInsight. Azure HDInsight rend les composants Hadoop de la distribution Hortonworks disponibles dans le Cloud et déploie et approvisionne des clusters de machines virtuelles nécessaires pour l’exécution de vos problèmes de calcul. Azure HDInsight fournit des configurations de cluster pour Apache Hadoop, Spark, HBase et Storm. L’offre Azure vous permet également d’utiliser des clusters personnalisés avec des actions de script. Au même titre qu’Amazon EMR, Microsoft Azure HDInsight est une offre qui est facturée en fonction des composants Hadoop utilisés, des types d’instances de machines virtuelles qui forment le cluster et du compte de stockage que vous aurez pris le cas échéant.
Hadoop Cloud Microsoft = instances Azure + instances HDInsight + abonnement stockage Azure
V-A. Fonctionnalités d’Azure HDInsight▲
La spécificité de l’offre Azure HDInsight est qu’elle fait partie d’un écosystème plus grand : Azure. Par conséquent, elle bénéficie des fonctionnalités de celle-ci. Nous allons énumérer de façon succincte celles qui nous semblent les plus importantes par rapport aux objectifs de ce chapitre et cet ouvrage.
- redimensionnement automatique des clusters en cours d'exécution : Azure HDInsight, tout comme Amazon EMR, offre la possibilité de redimensionner un cluster en cours d'exécution ;
- intégration avec l’Object Store blob Azure : les clusters que vous créez en Azure HDInsight peuvent exploiter les données directement depuis un service Cloud séparé, Azure Store blob(1) qui est le service Cloud de stockage d’Azure. Grâce à une interface HDFS, tous les composants de HDInsight peuvent fonctionner directement sur les données structurées ou non structurées dans le stockage d’objet blob. Azure Store blob n’est pas juste un endroit où les données sont stockées, il fait aussi office de système de fichiers distribué remplaçant le HDFS pour les clusters HDInsight, ce qui permet la mutualisation des données entre plusieurs comptes de stockage Azure blob, l’élasticité des ressources et la réplication/restauration géographique des données ;
- gouvernance : Azure offre des fonctionnalités de gouvernance qui permettent de l’intégrer dans la politique de gouvernance informatique de l’entreprise cliente. Ces fonctionnalités comprennent l’authentification unique (Single Sign-On – SSO), l’authentification multifacteur et la gestion des millions d’identités à travers Azure Active Directory, un service Cloud de gestion des identités et des authentifications. De plus, Azure HDInsight s’intègre avec Apache Ranger pour permettre l’attribution des niveaux de droit d’accès à des utilisateurs ou des groupes d’utilisateurs. Azure HDInsight est conforme aux normes HIPAA, PCI et SOC, garantissant un haut niveau de sécurité, à la fois de la plate-forme et des données des clients ;
- intégration à Hadoop : Azure HDInsight s’appuie sur la distribution HDP Hortonworks d’Hadoop. Elle offre 4 types de clusters indépendants : un cluster Hadoop, un cluster HBase, un cluster Spark et un cluster Storm. En d’autres termes, vous ne pouvez pas provisionner un cluster de machines virtuelles avec HBase ou Storm ou Spark ou Hadoop tournant au même moment dessus. HDInsight est également intégré aux outils décisionnels de la suite Microsoft tels que Power BI, Excel, SQL Server Analysis Services et SQL Server Reporting Services. Le cluster HDInsight peut être provisionné et déclenché à l’aide des scripts d’actions personnalisées, ce qui lui permet de s’intégrer à des applications externes. Actuellement, des scripts d’action ont été développés pour qu’un cluster HDInsight s’utilise avec les applications Datameer, Cask, AtScale et StreamSets et avec des environnements de développement utilisateur tels qu’Éclipse, Jupyter, IntelliJ ou Visual Studio.
V-B. Tarification d’Azure HDInsight▲
Les clusters HDInsight sont des approvisionnements d'instances de machines virtuelles ou de nœuds. Le client est facturé sur l'usage de ses nœuds sur une période donnée (par heure ou par mois). La facturation commence une fois que le cluster est créé et s'arrête lorsque le cluster est supprimé. La tarification HDInsight est fonction des 3 facteurs principaux suivants : le type de cluster, le type d’instance, la version de l’offre HDInsight, la région géographique et les services de support.
- type de cluster : la facturation varie en fonction du type de cluster que vous sélectionnez. Azure HDInsight offre le choix entre 4 types de cluster : le cluster Hadoop, le cluster HBase, le cluster Spark et le cluster Storm. Pour connaître le coût de chaque type de cluster, rapprochez-vous directement de Microsoft ;
-
type d’instance : Azure fournit des types d’instances optimisés, chacun pour un cas d’utilisation bien précis et pour un type de cluster précis. En d’autres termes, le type d’instance que vous sélectionnez est fonction du type de cluster que vous allez utiliser. Chaque type d’instance correspond à un ensemble de caractéristiques de performance spécifiques qui seront utilisées pour approvisionner les machines virtuelles de votre cluster. Microsoft Azure met à disposition 2 grandes catégories de types d’instances :
- les séries A, adaptées aux clusters qui exécutent des applications de requêtes de base et des modèles dans Hadoop et adaptées également aux clusters à hauts niveaux de performances, spécialisés dans le calcul intensif, la modélisation, les simulations, l’encodage vidéo, ainsi que les autres scénarios nécessitant une bande passante importante ou de nombreux calculs.,
- les séries D, adaptées aux clusters qui exécutent des applications nécessitant une faible latence et un accès disque SSD local ou des processeurs plus rapides sur Hadoop. Le tableau suivant donne un aperçu des caractéristiques de quelques configurations de machines disponibles dans les différentes séries ;
|
Type d’instance |
Nombre de Cœurs |
Mémoire RAM |
Stockage disque dur |
PRIX DE BASE / NŒUD |
|
A1 |
1 |
1.75 Go |
70 Go |
0,0675 €/heure |
|
A4 |
8 |
14 Go |
605 Go |
0,5397 €/heure |
|
A5 |
2 |
14 Go |
135 Go |
0,2952 €/heure |
|
A6 |
4 |
28 Go |
285 Go |
0,5987 €/heure |
|
A11 |
16 |
112 Go |
382 Go |
2,5636 €/heure |
|
D1 v2 |
1 |
3.5 Go |
50 Go |
0,1307 €/heure |
|
D2 v2 |
2 |
7 Go |
100 Go |
0,2623 €/heure |
|
D3 v2 |
4 |
14 Go |
200 Go |
0,5245 €/heure |
|
D11 v2 |
2 |
14 Go |
100 Go |
0,3205 €/heure |
|
D12 v2 |
4 |
28 Go |
200 Go |
0,6409 €/heure |
|
D13 v2 |
8 |
56 Go |
400 Go |
1,1536 €/heure |
|
D14 v2 |
16 |
112 Go |
800 Go |
2,0762 €/heure |
|
Tableau 5 : caractéristiques des types d'instances Azure avec leur prix |
En plus des caractéristiques des instances, HDInsight déploie un nombre différent de nœuds pour chaque type de cluster. Au sein d'un type de cluster donné, il existe différents rôles pour les divers nœuds, ce qui permet à un client de dimensionner ces nœuds dans un rôle donné en fonction de la charge de travail. Par exemple, les nœuds de calcul d'un cluster Hadoop peuvent être approvisionnés avec une grande quantité de mémoire si les analyses exécutées en ont besoin. Les clusters Hadoop pour HDInsight sont déployés avec deux rôles : nœud principal (2 nœuds) et nœud de données (au moins 1 nœud). Les clusters HBase pour HDInsight sont déployés avec trois rôles : les serveurs principaux (2 nœuds), les serveurs de région (au moins 1 nœud) et les nœuds principaux/Zookeeper (3 nœuds). Les clusters Spark pour HDInsight sont déployés avec trois rôles : le nœud principal (2 nœuds), le nœud de travail (au moins 1 nœud) et les nœuds Zookeeper (3 nœuds) (gratuit pour les nœuds Zookeeper de taille A1). Les clusters Storm pour HDInsight sont déployés avec trois rôles : les nœuds Nimbus (2 nœuds), les serveurs superviseurs (au moins 1 nœud) et les nœuds Zookeeper (3 nœuds). L’utilisation de R-Server implique un nœud de périphérie en plus de l’architecture de déploiement du cluster. Le tableau suivant récapitule la configuration minimale de chaque type de cluster. Pour plus de détails, rapprochez-vous de Microsoft.
|
Type de Cluster |
Nombre de rôles |
Description |
|
Cluster Hadoop |
2 |
Nœud principal (2 nœuds) |
|
Cluster HBase |
3 |
Serveurs principaux (2 nœuds), |
|
Cluster Spark |
3 |
Nœud principal (2 nœuds), |
|
Cluster Storm |
3 |
Nœuds Nimbus (2 nœuds) |
|
Tableau 6 : configuration de cluster par type de cluster |
- version de l’offre HDInsight : HDInsight est disponible en deux versions, la version standard et la version Premium. Les deux types de versions n’offrent pas les mêmes fonctionnalités, surtout en termes de gouvernance et de sécurité et ne sont pas facturés de la même façon. Les 2 tableaux ci-après illustrent respectivement les fonctionnalités et les prix de chaque version ;
|
Fonctionnalités de HDinsight |
STANDARD |
PREMIUM |
|
Mise à l’échelle illimitée |
✓ |
✓ |
|
Mise à l’échelle élastique |
✓ |
✓ |
|
Approvisionnement simple |
✓ |
✓ |
|
Haute disponibilité |
✓ |
✓ |
|
Contrat SLA |
✓ |
✓ |
|
Surveillance de base |
✓ |
✓ |
|
Mises à niveau et correctifs pour versions Hadoop |
✓ |
✓ |
|
Chiffrement des données au repos |
✓ |
✓ |
|
Passerelle sécurisée et nœuds Zookeeper |
✓ |
✓ |
|
Ranger (Hadoop sécurisé) + Intégration d’AD |
✓ |
|
|
Hadoop (Hive, Pig, Storm) |
✓ |
✓ |
|
Hadoop avec LLAP (requêtes interactives) |
✓ |
✓ |
|
HBase pour base de données NoSQL |
✓ |
✓ |
|
Storm pour les analyses de flux en temps réel |
✓ |
✓ |
|
Spark pour les requêtes SQL en mémoire, ML et les analyses de flux continus en temps réel |
✓ |
✓ |
|
R-Server pour l’apprentissage automatique en parallèle |
✓ |
✓ |
|
Tableau 7 : fonctionnalités de chaque version d'HDInsight |
||
|
Version HDInsight |
Type de cluster |
R-SERVER |
|
Cluster Standard |
Prix de base / Nœud-Heure |
Prix de base / Nœud-Heure + 0,0169 €/Cœur-heure |
|
Cluster Premium |
Prix de base / Nœud-Heure + 0,0169 €/Cœur-heure |
Prix de base / Nœud-Heure + 0,0337 €/Cœur-heure |
|
Tableau 8 : Tarification des versions d'HDInsight |
||
- région géographique : la facturation d’Azure HDInsight dépend également de la localisation géographique de vos clusters. Actuellement, Azure est mis en disponibilité générale dans 30 régions du monde et 8 autres régions seront bientôt annoncées ;
- services de support : en plus des 4 critères précédents, vous pouvez optionnellement souscrire à des services supplémentaires pour vos clusters HDInsight. Microsoft Azure met à disposition 3 services supplémentaires : le service de stockage de données (Azure blob Storage), le service de transfert de données et le service support. Vous avez également la possibilité de souscrire à R-Server pour les analyses statistiques. Notez que ces services sont facturés séparément ;
Avec tous ces critères, il vous est peut-être difficile de vous y retrouver. Nous allons utiliser un exemple tiré du site support de Microsoft pour illustrer un exemple de facturation. Supposons que vous souscrivez à un cluster dans la région est des États-Unis avec 2 nœuds principaux D13 v2, 3 nœuds de données D12 v2 et 3 Zookeeper D11, la facturation est la suivante dans les deux scénarios :
- Utiliser HDInsight Standard sur un cluster de cœurs HDInsight :
2 x 1,15 €/heure + 3 x 0,64 €/heure + 3 x 0,32 €/heure) = 5,1914 €/heure - Utiliser HDInsight Premium sur un cluster de cœurs HDInsight avec R-Server :
2 x 1,15 €/heure + 3 x 0,64 €/heure + 3 x 0,32 €/heure + (2 x 8 + 3 x 4 + 3 x 2) x 0,0337 €/Cœur-heure = 6,3382 €/heure
Tout comme avec Amazon EMR, les tarifs et la composition de l’offre complète d’Azure HDInsights sont en renouvellement permanent. Renseignez-vous directement auprès de Microsoft pour les informations à jour ou n’hésitez pas à vous rendre sur le site officiel de l’offre Azure HDInsight.
Lorsque vous devez conseiller votre client ou vous informer quant à l’offre Cloud à sélectionner pour vos problèmes Hadoop (précisément le stockage de données dans les services Cloud), soyez conscient de l’impact des réglementations. L’état américain, par exemple, possède une loi appelée Patriot Act qui l’autorise en cas de nécessité à investiguer les données hébergées dans le Cloud des entreprises américaines, indépendamment de la localisation de leurs data centers dans le monde. Ainsi, si l’état américain le juge nécessaire, il peut accéder aux données stockées dans le Cloud de Microsoft ou Amazon même si les serveurs qui stockent ces données sont hébergés sur le territoire européen. C’est une erreur très courante de croire que cette loi s’applique uniquement sur le sol américain. De plus, même si vous souscrivez à une offre Cloud d’une entreprise américaine en Europe, rien ne garantit que vos données restent hébergées dans les data centers en Europe.
VI. Conclusion▲
Nous sommes arrivés au terme de ce tutoriel. En guise de conclusion, ce qu’il faut retenir est que le Cloud Computing est un modèle économique où un fournisseur Cloud met à disposition ses ressources informatiques via Internet à d’autres entreprises et que celles-ci payent en fonction de leur usage. D’un point de vue technique, le Cloud c’est de la virtualisation et d’un point de vue économique, c’est du leasing. Dans ce tutoriel, nous vous avons montré comment fonctionne le Cloud aussi bien sur ses aspects techniques que sur ses aspects économiques, nous vous avons ensuite montré comment Hadoop pouvait être utilisé dans le Cloud, nous avons fourni les informations sur les deux offres Cloud Hadoop majeures du marché, à savoir Amazon EMR et Microsoft Azure HDInsights. Vous devez savoir qu’en dehors de EMR et Azure HDInsights, 2 autres offres Cloud spécialement ciblées sur le Big Data existent :
- l’offre Cloud App d’OVH : https://www.ovh.com/fr/cloud-apps/hadoop.xml
- et l’offre Google Cloud Platform : https://cloud.google.com/hadoop/?hl=fr
À terme, ces offres pourraient devenir aussi compétitives que celles d’Amazon et Microsoft. Comme vous avez pu le constater vous-même tout au long de ce tutoriel, le cloud est un sujet très vaste qui fait appel à plusieurs technologies. Dans notre ouvrage « Maîtrisez l’utilisation des technologies Hadoop », nous couvrons de manière exhaustive le sujet du Cloud Computing. Plus précisément, l’utilisation opérationnelle du Cloud en Big Data. Vous y trouverez la taxonomie des offres Cloud, les détails sur la virtualisation de données, Hadoop-as-a-Service, 7 critères à utiliser pour sélectionner un fournisseur Cloud fiable, l’impact des législations en Cloud et quelques stratégies pour minimiser l’atteinte à l’intégrité des données hébergées dans le Cloud.
VII. Note de la rédaction developpez.com▲
La rédaction de développez.com tient à remercier ![]() Juvénal CHOKOGOUE qui nous a autorisés à publier cet article.
Juvénal CHOKOGOUE qui nous a autorisés à publier cet article.
Nous remercions également à ![]() Christophe pour la relecture technique et
Christophe pour la relecture technique et ![]() escartefigue pour la relecture orthographique.
escartefigue pour la relecture orthographique.