



I. Introduction▲
Les entreprises qui souhaitent exploiter leurs données utilisent aujourd'hui Hadoop d'une manière ou d'une autre. Cependant, la valorisation des données a entraîné un foisonnement de problématiques qui nécessitent des réponses technologiques aussi différentes les unes que les autres. Hadoop a beau être le socle technique du Big Data, il n'est pas capable à lui seul de répondre à toutes ces problématiques. À chaque nouvelle problématique, les développeurs sont obligés de coder de nouveaux modules ce qui, en plus d'être frustrant à mettre en production (à cause généralement de l'incompatibilité entre les environnements et la complexité liée aux versions des composants d'Hadoop), réduit la productivité des équipes de développement, qui passent désormais leur temps plus au débogage du code qu'au développement.
C'est pour résoudre tous ces problèmes qu'un ensemble de technologies, regroupées sous le nom d'écosystème Hadoop, a été développé. L'écosystème Hadoop fournit une collection d'outils et technologies spécialement conçus pour faciliter le développement, le déploiement et le support des solutions Big Data. Actuellement, pas mal de développeurs sont en train de travailler sur l'écosystème Hadoop et offrent leurs travaux en open source à la fondation Apache. Apache est aujourd'hui le dépositaire de la majorité de ces technologies. Après incubation des projets qu'elle reçoit des développeurs, elle a inclus dans Hadoop une série spécifique de logiciels et d'outils pour favoriser la productivité des développeurs et pour éviter que les entreprises aient à chaque fois besoin de développer elles-mêmes des outils compatibles avec Hadoop afin de déployer ses solutions sur le cluster. La définition de cet écosystème est importante, car il facilite l'adoption d'Hadoop et permet aux entreprises de surmonter les challenges de la valorisation de leurs données.
La carte heuristique suivante présente de façon globale l'écosystème Hadoop.
|
|
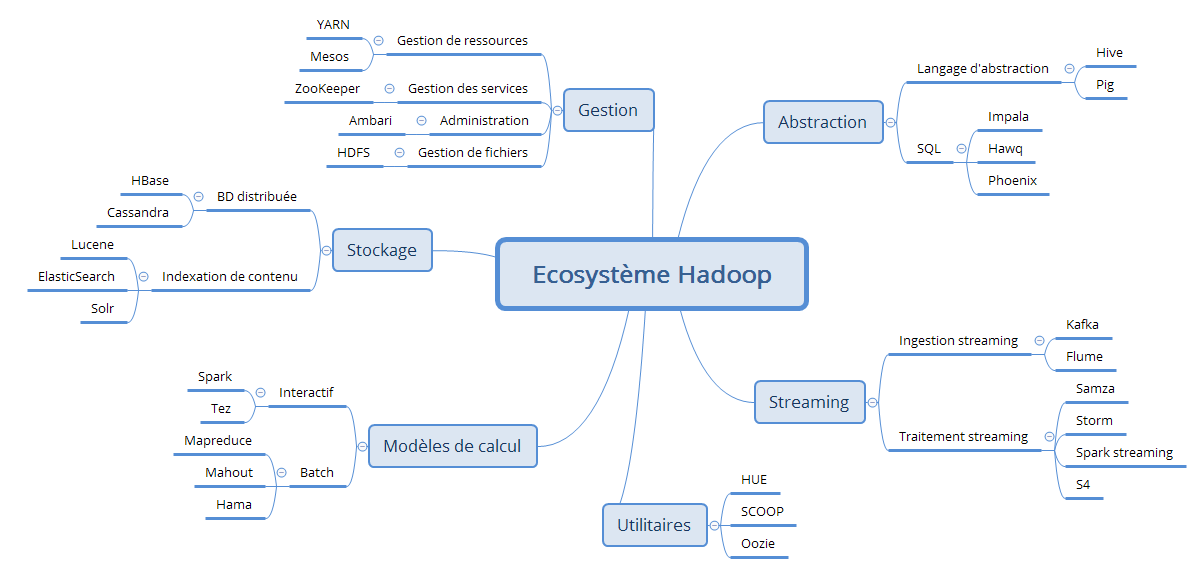
Maintenant, passons au vif du sujet. La configuration de base de l'écosystème Hadoop contient les technologies suivantes : Spark, Hive, PIG, HBase, Sqoop, Storm, ZooKeeper et Oozie.
II. Spark▲
Avant d'expliquer ce qu'est Spark, rappelons que pour qu'un algorithme puisse s'exécuter sur plusieurs nœuds d'un cluster Hadoop, il faut qu'il soit parallélisable. Ainsi, on dit d'un algorithme qu'il est « scalable » s'il est parallélisable (et peut donc profiter de la scalabilité d'un cluster). Hadoop est une implémentation du modèle de calcul MapReduce. Le problème avec le MapReduce est qu'il est bâti sur un modèle de Graphe Acyclique Direct. En d'autres termes, l'enchaînement des opérations du MapReduce s'exécute en trois phases séquentielles directes et sans détour (Map -> Shuffle -> Reduce). Aucune phase n'est itérative (ou cyclique). Le modèle acyclique direct n'est pas adapté à certaines applications, notamment celles qui réutilisent les données à travers de multiples opérations, telles que la plupart des algorithmes d'apprentissage statistique, itératifs pour la plupart, et les requêtes interactives d'analyse de données. Spark est une réponse à ces limites. C'est un moteur de calcul qui effectue des traitements distribués en mémoire sur un cluster. Autrement dit, c'est un moteur de calcul in-memory distribué. En tant que tel, il excelle sur les tâches itératives et interactives, tout en conservant la scalabilité et la tolérance aux pannes du cluster. Il fournit une bibliothèque de classes d'implémentation Java d'algorithmes d'apprentissage statistique et de Machine Learning pour l'exécution dans un cluster Hadoop. Ces classes peuvent être exploitées à l'aide d'un langage de programmation comme Scala, Java, Python ou tout autre langage qui est compatible avec Spark. En réalité, bien que présent dans l'écosystème Hadoop, Spark est un framework indépendant d'Hadoop. Il possède et utilise son propre modèle de calcul, indépendamment du MapReduce (ceci est possible grâce au YARN). Comparativement au MapReduce qui fonctionne en mode batch, le modèle de calcul de Spark fonctionne en mode interactif, c'est-à-dire qu'il monte les données en mémoire avant de les traiter et est, de ce fait, très adapté au traitement de Machine Learning. Spark remplace le modèle de calcul Mahout, qui lui utilisait le MapReduce pour l'exécution et la parallélisation des algorithmes de Machine Learning (et de ce fait fonctionnait en mode batch).
Voici un bon tutoriel pour apprendre à développer en Spark avec Java : Introduction à Spark pour l'interrogation de données massives.
III. Hive▲
Hive est une infrastructure informatique similaire au Data Warehouse qui fournit des services de requêtes et d'agrégation de très gros volumes de données stockées sur un système de fichiers distribué de type HDFS. Hive fournit un langage de requête basé sur le SQL (norme ANSI-92) appelé HiveQL (Hive Query Language), qui est utilisé pour adresser des requêtes aux données stockées sur le HDFS. Le HiveQL permet également aux utilisateurs avancés/développeurs d'intégrer des fonctions MapReduce directement à leurs requêtes, pour couvrir une plus large palette de problèmes de gestion de données. Cette capacité de plug-in du MapReduce sur le HiveQL s'appelle les UDF (User Defined Function). Lorsque vous écrivez une requête en HiveQL, cette requête est transformée en job MapReduce et est soumise au JobTracker pour exécution par Hive. Étant donné que les données de la requête ne sont pas stockées dans une table, comme dans le cas d'une requête SQL classique, Hive s'appuie sur une couche de stockage de données installée sur Hadoop, à l'exemple d'HCatalog, pas pour le stockage des données du HDFS mais pour le stockage des métadonnées des requêtes des utilisateurs. Voici un exemple de requête écrite en HiveQL : « Trouver la température maximale par année. »
2.
3.
4.
USE DEFAULT ;
CREATE TABLE records (YEAR string, temperature INT, quality INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' ;
LOAD DATA LOCAL 'data/sample.txt' OVERWRITE INTO TABLE records ;
SELECT year, MAX(temperature) FROM records WHERE temperature !=9999 AND (quality == 0 OR quality == 1) GROUP BY year ;
Si vous souhaitez aller plus loin sur Hive, vous pouvez vous rendre sur ce tutoriel : Le SQL dans Hadoop : HiveQL et Pig
IV. Pig▲
Pig est un environnement d'exécution de flux interactifs de données sous Hadoop. Il est composé de deux éléments :
- un langage d'expression de flux de données, appelé le Pig Latin ;
- et un environnement Interactif d'exécution de ces flux de données.
Le langage offert par Pig, le Pig Latin, est à peu près similaire au langage de scripting tels que Perl, Python ou Ruby. Cependant, il est plus spécifique que ces derniers et se décrit mieux sur le terme « langage de flux de données » (data flow language). Il permet d'écrire des requêtes sous forme de flux séquentiels de données sources pour obtenir des données « cibles » sous Hadoop, à la façon d'un ETL. Ces flux sont ensuite transformés en fonctions MapReduce, qui sont enfin soumises au jobtracker pour exécution. Pour faire simple, Pig c'est l'ETL d'Hadoop. Programmer en Pig Latin revient à décrire, sous forme de flux indépendants mais imbriqués, la façon dont les données sont chargées, transformées et agrégées à l'aide d'instructions Pig spécifiques, appelées opérateurs. La maîtrise de ces opérateurs est la clé de la maîtrise de la programmation en Pig Latin, d'autant plus qu'ils ne sont pas nombreux, relativement au Hive par exemple. L'exemple précédent en HiveQL donne ceci en Pig Latin :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
records = LOAD 'data/samples.txt' AS (year: chararray, temperature : int, quality: int);
filtered_records = FILTER records BY temperature != 9999
AND
(
quality == 0
OR quality == 4
)
;
grouped_records = GROUP filtered_records BY year ;
Max_temp = FOREACH grouped_records GENERATE group, MAX filtered_records.temperature
)
DUMP max_temp ;
Si vous souhaitez aller plus loin sur Hive, vous pouvez vous rendre sur ce tutoriel : Le SQL dans Hadoop :HiveQL et Pig
V. Hbase▲
Avant de parler de HBase, nous allons rappeler que les SGBDR, qui sont jusqu'à présent utilisés pour la gestion des données, ont montré très rapidement leurs limites face d'une part la forte volumétrie des données et, d'autre part, face à la diversité des données. En effet, les SGBDR sont conçus pour gérer uniquement des données structurées (table de données en ligne/colonnes). De plus, l'augmentation du volume des données augmente le temps de latence des requêtes. Cette latence est préjudiciable dans le cadre de nombreux métiers requérant des réponses en temps quasi réel. Autre facteur limitant des SGBDR, ceux-ci n'arrivent à assurer la distribution des données que sur quelques nœuds (5 au maximum). En d'autres termes, les SGBDR n'ont pas été conçus avec les exigences de scalabilité à l'esprit, mais plutôt avec l'esprit d'exigences de cohérence et de non-redondance. Pour répondre à ces limites de nouveaux SGBD, dit « NoSQL », ont vu le jour. Ceux-ci n'imposent pas de structure particulière aux données, sont capables de distribuer le stockage et la gestion des données sur plusieurs nœuds et sont scalables. À titre de rappel, la scalabilité signifie que la performance du système reste stable avec l'augmentation de la charge de traitement. HBase fait partie de cette catégorie de SGBD.
HBase est un SGBD distribué, orienté-colonne qui fournit l'accès en temps réel aussi bien en lecture qu'en écriture aux données stockées sur le HDFS. Là où le HDFS fournit un accès séquentiel aux données en batch, non approprié pour des problématiques d'accès rapide à la donnée comme le Streaming, HBase couvre ces lacunes et offre un accès rapide aux données stockées sur le HDFS. Il faut comprendre par là que HBase est perçu par le HDFS comme un client à qui il fournit les données. HBase a été conçu pour :
- ne fonctionner que sur un cluster Hadoop ;
- être linéairement scalable, c'est-à-dire qui supporte l'ajout de nœuds au cluster ;
- stocker de très grosses volumétries de données épaves, c'est-à-dire des données à structure irrégulière, avec plein de valeurs nulles comme les matrices creuses en Algèbre. Nous y reviendrons plus bas ;
- fournir un accès en temps réel à cette grosse volumétrie de données, aussi bien pour les opérations de lecture que d'écriture sur le HDFS ;
- s'appuyer sur des modèles de calculs distribués tels que le MapReduce (et donc tous ses langages d'abstraction tels que Hive, Pig, Cascading…) pour l'exploitation de ses données.
Il a été conçu à partir du SGBD de Google « Big Table » et est capable de stocker de très grosses volumétries de données (milliard de lignes/colonnes). Il dépend de ZooKeeper, un service de coordination distribuée pour le développement d'applications.
Supposons que nous souhaitons interroger une table HBase. On écrira en Shell une commande « scan » selon la syntaxe suivante :
scan '< TABLE>', {COLUMNS => ['<Colonne1>',…,'<ColonneN>'], VERSIONS => <nombre de versions retournées>, FILTER => <critère filtre>, LIMIT = <nbre_de_valeurs_renvoyées> ...}Par exemple :
scan 'customers, {COLUMNS => ['personal:customer_name', 'public: enterprise'], VERSIONS => 10, FILTER => "PrefixFilter('CC09877')" }Cette requête renvoie les données dont les rowKeys sont préfixées « CC ». Vous pouvez transférer les résultats renvoyés par la requête en utilisant la commande Shell suivante :
echo "commande hbase shell" | hbase shell > fichier.txtVI. Sqoop▲
Sqoop ou SQL-to-Hadoop est un outil qui permet de transférer les données d'une base de données relationnelle au HDFS d'Hadoop et vice-versa. Il est intégré à l'écosystème Hadoop et est ce que nous appelons le planificateur d'ingestion des données dans Hadoop. Vous pouvez utiliser Sqoop pour importer des données des SGBDR tels que MySQL, Oracle ou SQL Server au HDFS, transformer les données dans Hadoop via le MapReduce ou un autre modèle de calcul et les exporter en retour dans le SGBDR. Nous l'appelons planificateur d'ingestion des données parce que tout comme Oozie (plus bas), il automatise ce processus d'import/export et en planifie le moment d'exécution. Tout ce que vous avez à faire, en tant qu'utilisateur, est d'écrire les requêtes SQL qui vont être utilisées pour effectuer le mouvement d'import/export. Par ailleurs, Sqoop utilise le MapReduce pour importer et exporter les données, ce qui est efficace et tolérant aux pannes. La figure suivante illustre particulièrement bien les fonctions de Sqoop.
|
|

|
Figure 1 : Sqoop tourne autour de deux activités réparties sur ses deux utilitaires : l'utilitaire d'import et l'utilitaire d'export. |
Supposons que nous souhaitons exporter une table MySQL appelée `jvc_hadoop` dans Hadoop. Nous souhaitons importer la table dans le répertoire HDFS `lab/import/data`. Le script Sqoop d'import sera le suivant :
$ sqoop import \
--connect jdbc:mysql://localhost/sqoop_test \
--table jvc_hadoop \
--split -by id_jvc \
--num-mappers 6 \
--target-dir lab/import/dataVII. Storm▲
Pour comprendre Storm, il faut comprendre la notion d'architectures lambda (λ) et pour comprendre l'intérêt des architectures lambda, il faut comprendre le concept d'objets connectés. Les objets connectés ou Internet des objets (IoT - Internet of Things en anglais) représente l'extension d'Internet à nos vies quotidiennes. Par exemple, on parle de voiture connectée, bracelet connecté, montre connectée, etc. Le principe général des objets connectés est le suivant : des capteurs sont intégrés dans un objet (par exemple téléphone, voiture, thermostat, montre, etc.) qui captent, en temps réel, le comportement de l'objet et transfèrent les données captées à une application via un réseau (Wi-Fi, Bluetooth, etc.). cette application traite les données et, soit prédit le comportement de l'objet ou de l'utilisateur de l'objet, soit déclenche une action au niveau de l'objet, soit prescrit des recommandations d'action à l'utilisateur de l'objet. On dénombre actuellement 15 milliards d'objets connectés dans le monde et, d'après une enquête menée par Cisco en 2013, ils devraient atteindre la barre des 50 milliards en 2020. Autant vous dire que le futur du « Big Data » s'annonce donc IoT. Ce qui nous intéresse ici c'est la vitesse avec laquelle les données de capteurs sont créées et traitées. Les modèles que vous connaissez, tels que les modèles de calcul Batch, ne sont pas adaptés aux problématiques temps réel que soulève l'IoT. Même les modèles de calcul interactif ne sont pas adaptés pour faire du traitement continu en temps réel. À la différence des données opérationnelles produites par les systèmes opérationnels d'une entreprise comme la finance, le marketing, qui même lorsqu'elles sont produites en streaming peuvent être historisées pour un traitement ultérieur, les données produites en streaming dans le cadre des phénomènes comme l'IoT ou Internet se périment (ou ne sont plus valides) dans les instants qui suivent leur création et exigent donc un traitement immédiat. Cette combinaison unique de continuité de création de données et rapidité dans leur traitement, que nous qualifions de Streaming temps réel, est l'une des plus grandes problématiques de calcul qui s'annonce actuellement et dans le futur. En dehors des objets connectés, les problématiques métier comme la lutte contre la fraude, l'analyse des données de réseaux sociaux, la géolocalisation exigent des temps de réponse très faibles, quasiment de l'ordre de moins d'une seconde, et peuvent également être qualifiées de problématiques Streaming temps réel.
Pour résoudre cette problématique dans un contexte Big Data, des architectures dites λ ont été mises sur pied. Ces architectures ajoutent au MapReduce deux couches de traitements supplémentaires pour la réduction des temps de latence. Storm est une implémentation logicielle de l'architecture λ. Il permet de développer sous Hadoop des applications qui traitent les données en temps réel (ou presque).
Le classique exemple WordCount (le comptage des mots) s'écrit en Storm de la façon suivante en utilisant Flux, l'un de ses langages d'abstraction.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
FixedBatchSpout spout = new FixedBatchSpout(new Fields("sentence"), 3,
new Values("the cow jumped over the moon"),
new Values("the man went to the store and bought some candy"),
new Values("four score and seven years ago"),
new Values("how many apples can you eat"));
spout.setCycle(true);
TridentTopology topology = new TridentTopology();
TridentState wordCounts = topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"))
.parallelismHint(6);
Développer les architectures λ nous emmènerait beaucoup trop loin des objectifs de ce tutoriel. Si vous souhaitez en savoir plus à ce propos, nous vous recommandons la lecture du chapitre 9 de notre ouvrage Hadoop - Devenez opérationnel dans le monde du Big Data.
VIII. ZooKeeper▲
La synchronisation ou coordination de la communication entre les nœuds lors de l'exécution des tâches parallèles est l'un des problèmes les plus difficiles dans le développement d'applications distribuées. Pour résoudre ce problème, Hadoop a introduit dans son écosystème des outils dits de coordination de service, en l'occurrence ZooKeeper. ZooKeeper prend en charge la complexité inhérente de la synchronisation de l'exécution des tâches distribuées dans le cluster et permet aux autres outils de l'écosystème Hadoop de ne pas avoir à gérer ce problème eux-mêmes. Il permet également aux utilisateurs de pouvoir développer des applications distribuées sans être des experts de la programmation distribuée. Sans entrer dans les détails complexes de la coordination des données entre les nœuds d'un cluster Hadoop, ZooKeeper fournit un service de configuration distribué, un service de distribution et un registre de nommage pour les applications distribuées. ZooKeeper est le moyen utilisé par Hadoop pour coordonner les jobs distribués. Il est assez simple d'utilisation. Il expose un ensemble de méthodes via une API, une bibliothèque de classes Java qui contient des méthodes que vous pouvez appeler directement dans vos applications pour enregistrer des données partagées par plusieurs processus dans son registre. Par exemple les méthodes :
Create() : crée un nœud de données (znode) dans l'espace de nom du registre ;
Delete() : supprime un nœud.
IX. Oozie▲
Par défaut, Hadoop exécute les jobs au fur et à mesure qu'ils sont soumis par l'utilisateur, sans tenir compte de la relation qu'ils peuvent avoir les uns avec les autres. Or, les problématiques pour lesquelles on utilise Hadoop demandent généralement la rédaction d'un ou de plusieurs jobs complexes. Supposons que pour résoudre le problème de comptage des mots de tweets, nous ayons besoin de chaîner l'exécution de deux jobs. Lorsque les deux jobs seront soumis au JobTracker (ou à YARN), celui-ci va les exécuter sans faire attention au lien qui existe entre eux, ce qui risque de causer une erreur (exception) et d'entraîner l'arrêt du code. Comment fait-on pour gérer l'exécution de plusieurs jobs qui sont relatifs au même problème ? Pour gérer ce type de problème, la solution la plus simple actuellement consiste à utiliser un planificateur de jobs, en l'occurrence Oozie. Oozie est un planificateur d'exécution des jobs qui fonctionne comme un service sur un cluster Hadoop. Il est utilisé pour la planification des jobs Hadoop et, plus généralement, pour la planification de l'exécution de l'ensemble des jobs qui peuvent s'exécuter sur un cluster, par exemple un script Hive, un job MapReduce, un job Hama, un job Storm, etc. Il a été conçu pour gérer l'exécution, immédiate ou différée, de milliers de jobs interdépendants sur un cluster Hadoop automatiquement. Pour utiliser Oozie, il suffit de configurer deux fichiers XML : un fichier de configuration du moteur Oozie et un fichier de configuration du workflow des jobs. La figure suivante illustre un workflow Oozie.
|
|

|
Figure 2 : workflow Oozie |
Bien évidemment, vous l'aurez compris, il est impossible de développer de façon exhaustive toutes ces technologies de l'écosystème Hadoop dans un tutoriel. Si vous souhaitez aller plus loin dans l'étude de l'écosystème Hadoop, cliquez sur le lien suivant pour apprendre ElasticSearch : http://www.data-transitionnumerique.com/extrait-ecosystme-hadoop/.
X. Note de la rédaction de Developpez.com▲
La rédaction de développez.com tient à remercier Juvénal CHOKOGOUE, qui nous a autorisés à publier ce tutoriel.