



I. Introduction▲
La variété des formats de fichiers disponibles est l'un des plus grands problèmes dans l'indexation de contenu. Il faut que tous les fichiers à indexer soient stockés sur un format de fichier identique pour pouvoir y rechercher du contenu, ce qui est rarement le cas. C'est pour gérer ces problèmes que des moteurs NoSQL formels auxquels des fonctionnalités d'indexation et de recherche de contenu ont été ajoutées, ont été créés. Apache Solr et ElasticSearch sont deux de ces types de moteur. Apache Solr et ElasticSearch sont des moteurs NoSQL d'indexation de contenu scalables, qui s'appuient sur Apache Lucene, une bibliothèque d'indexation de contenu (nous y reviendrons plus loin), pour fournir des fonctionnalités d'indexation et de recherche de contenu. Là où Apache Lucene ne gère pas le stockage des documents, ces deux moteurs fournissent le support de stockage des données de sorte que l'indexation et la recherche puissent se faire directement dans le moteur. Malgré l'ancienneté d'Apache Solr, ElasticSearch est depuis 2010 très utilisé et c'est sur la base de cette popularité que nous l'avons choisi pour étude dans ce tutoriel. Vous y apprendrez les concepts de base d'ElasticSearch, ses principes de fonctionnement et son exploitation opérationnelle pour la recherche de contenu.
II. Spécificité d'ElasticSearch▲
Depuis sa sortie en 2010, ElasticSearch est devenu extrêmement populaire. Il a été développé la même année par Shay Banon(1) qui le commercialise via la société Elastic qu'il a créée. Malgré son aspect commercial et le fait qu'il ne fasse pas partie de la fondation Apache, ElasticSearch est open source. Formellement, ElasticSearch est un moteur distribué de stockage, de recherche et d'analyse de contenu. En tant que moteur de stockage, il stocke les données en format JSON, annulant ainsi le besoin de joindre à son application de recherche un support de stockage ; en tant que moteur de recherche, il utilise Apache Lucene pour les fonctionnalités d'indexation et de recherche de contenu sur ces documents JSON et en tant que moteur d'analyse de contenu, il s'appuie sur Logstash, un logiciel de gestion de logs et Kibana, une plateforme d'exploration et de visualisation des données, pour effectuer des analyses sur les données qu'il stocke. Sa particularité lui vient du fait qu'il s'interroge à partir d'une API REST, est accessible à partir du protocole HTTP et utilise le format JSON aussi bien pour le stockage des données que pour le renvoi des réponses de requêtes. Les standards HTML, REST et JSON le rendent facile à intégrer avec d'autres applications, simple à utiliser pour les utilisateurs. De plus, le fait qu'il utilise le JSON pour le stockage des données rend l'exploitation des données possible à partir de n'importe quel langage de programmation possédant des API permettant de lire du JSON. Les aspects distribués d'ElasticSearch lui permettent d'effectuer les recherches de contenu très rapidement, dans l'ordre de la seconde (Moins de 100 millisecondes en moyenne en fonction de la volumétrie des données et des caractéristiques du cluster selon les évaluations des experts.) Toute interaction avec ElasticSearch se fait à travers son API REST qui vous permet d'envoyer des requêtes HTTP.
Traditionnellement, les moteurs de recherche de contenu sont déployés sur des moteurs de base de données pour fournir aux applications développées sur ces bases de données des fonctionnalités d'indexation et de recherche. Historiquement, ceci a été le cas parce que les moteurs de recherche de contenu n'offraient pas de support de stockage persistant sur lequel directement effectuer les recherches. ElasticSearch est l'un des moteurs de recherche de contenu moderne qui fournit à la fois le support de stockage NoSQL, l'indexation et la recherche de contenu, et l'Analytics. ElasticSearch est un moteur NoSQL orienté-document, au même titre que MongoDB ou RavenDB et il fournit toutes les fonctionnalités de stockage distribué que ce type de moteur offre. Cependant, vous pouvez aussi utiliser ElasticSearch avec d'autres moteurs de base de données. Si vous voulez développer une nouvelle application ou si vous voulez ajouter des fonctionnalités de recherche de contenu dans une application existante, l'API REST est l'une des fonctionnalités qui rendent ElasticSearch attractif. En effet, ElasticSearch expose ses fonctionnalités à travers cette API REST, vous permettant d'écrire vos requêtes en JSON, de recevoir les résultats des requêtes en JSON et d'effectuer l'ensemble de vos interactions avec ElasticSearch via cette même API. Dans la partie suivante, nous allons entrer dans l'organisation et le fonctionnement interne d'ElasticSearch.
III. L'indexation et la recherche de contenu dans ElasticSearch▲
Dans ce point, nous allons vous permettre de comprendre comment l'indexation et la recherche de contenu se passent dans ElasticSearch.
III-A. Les concepts clés d'ElasticSearch▲
Pour comprendre comment l'indexation et la recherche de contenu se passent dans ElasticSearch, il faut que vous compreniez l'ensemble des concepts clés qu'il met en œuvre et la relation qui existe entre ces concepts. ElasticSearch possède six concepts qu'il est fondamental de comprendre pour pouvoir l'utiliser efficacement : le nœud, le cluster, l'index, le type/mapping, le document, la partition (shard) et la réplique.
- Le nœud : en ElasticSearch, un nœud fait référence à une instance d'exécution du logiciel ElasticSearch. Autrement dit, c'est un processus applicatif qui est exécuté sur une machine. Une machine ou un serveur virtuel peut exécuter une ou plusieurs instances ou nœuds ElasticSearch en fonction de ses ressources. Les nœuds peuvent également s'exécuter sur un cluster de machines lorsqu'il y a besoin de la haute disponibilité ;
- Le cluster : un cluster ElasticSearch est un ensemble d'un ou plusieurs nœuds. Comme nous l'avons dit précédemment, un nœud fait référence à une instance d'ElasticSearch, par conséquent un cluster entier peut tourner sur une machine virtuelle. Le cluster fournit l'indexation collective et la distribution des requêtes de recherche à travers tous les nœuds du cluster ;
- L'index : dans la terminologie ElasticSearch, un index est un ensemble de documents JSON. Nous y reviendrons plus bas ;
- Le type : encore appelé Mapping, le type fait référence à un ensemble de documents qui partagent un ensemble de champs communs, présent dans le même index. Le Mapping est l'un des éléments qui distinguent d'ailleurs ElasticSearch d'Apache Solr. Là où Solr exige que tous les documents JSON aient la même structure, ElasticSearch les stocke en l'état, mais utilise le type pour les catégoriser. C'est pourquoi on dit qu'ElasticSearch est « sans schéma » ou « n'impose pas de schéma à priori ». Ainsi, ces expressions que vous allez sans doute rencontrer ne font aucunement référence au schéma dans le sens SGBDR du terme. Nous y reviendrons plus bas ;
- L'indice : c'est le container logique des types. Le concept d'indice introduit les notions d'index ElasticSearch et index Lucene. Nous y reviendrons plus bas ;
- Le document : c'est un ensemble de champs ou propriétés définis de façon spécifique dans le format JSON. Chaque document appartient à un type et réside dans un index. À chaque document est associé un identifiant unique appelé UID ;
- La partition : de sa traduction originale Shard, une partition est une partie de l'index. Les index sont horizontalement partitionnés en shards, tout comme les tables dans un SGBD sont partitionnées en lignes. En d'autres termes, les documents JSON sont partitionnés par objet (par champs) et ces partitions sont réparties dans les nœuds du cluster ElasticSearch. Chaque partition contient toutes les propriétés (champs) du document, mais moins d'objets JSON. La distribution des partitions dans le cluster fait distinguer la notion de partition primaire et partitions secondaires. Nous allons y revenir plus bas ;
- La réplique : les index et les partitions sont répliqués à travers les nœuds du cluster pour accroître la haute disponibilité des traitements en cas de panne. De plus, les répliques permettent de paralléliser les traitements de recherche de contenu dans le cluster, ce qui accroît la performance d'ElasticSearch.
III-B. L'indexation de contenu dans ElasticSearch▲
Dans ElasticSearch, l'unité est le document. En d'autres termes, l'index dans ElasticSearch c'est l'ensemble des documents qui sont stockés dans le moteur. Les documents sont enregistrés au format JSON. La structure hiérarchique du format JSON permet à ElasticSearch d'indexer tout le contenu des documents. À titre de rappel, le contenu d'un document JSON est formellement organisé sous forme d'objets. Chaque objet est l'équivalent d'une ligne dans une table de base de données relationnelle. Les documents sont organisés en séries de propriétés, qui sont l'équivalent des colonnes dans le monde des bases de données relationnelles. La figure ci-après illustre un document JSON. Bien que basique, il est important de comprendre cette organisation, elle vous servira pour comprendre l'organisation des données dans ElasticSearch et la façon dont les requêtes de recherche y sont exécutées.
|
|

|
Figure 10-1 document JSON |
Vous pouvez voir que le document JSON mis en avant dans la figure ci-dessus possède deux objets (ou deux lignes), il possède plusieurs propriétés. Le premier objet a pour propriété firstName la valeur Juvénal, tandis que le deuxième objet pour la même propriété a pour valeur Julie. Ce document a pour caractéristique de posséder la même structure pour tous les objets (les propriétés sont les mêmes d'un objet à un autre). Cependant, dans la vraie vie, le schéma ou la structure de données des documents est rarement la même. Dans la recherche de contenu, l'un des problèmes majeurs que l'on rencontre est la variété des formats de fichiers et des structures des données, ce qui complexifie l'indexation des données sur ces fichiers. ElasticSearch se démarque sur ce point en supportant toute forme de structure JSON. En d'autres termes, ElasticSearch indexe nativement des documents JSON dont la structure n'est pas identique d'un objet à l'autre ou d'un document à l'autre. C'est l'un des points qui le différencie de son rival, Apache Solr, qui exige que tous les documents JSON aient la même structure. Comment ElasticSearch réussit-il à indexer du contenu sur les documents JSON dont la structure est différente ? En introduisant la notion de type ou de type de document. Certains préfèrent parler de Mapping de document pour désigner le type. Formellement, le typage de document consiste à regrouper les documents qui partagent les mêmes propriétés (champs) dans le même indice. ElasticSearch gère le stockage des données d'une façon logique (conceptuelle). Ainsi, l'indice est le container logique de l'ensemble des documents qui ont le même type, même si physiquement tous ces documents sont persistés au même endroit sur le disque dur. La notion d'indice permet d'introduire les concepts d'index ElasticSearch et index Lucene. Dans le point suivant, vous allez comprendre leur importance. L'index ElasticSearch ou index au sens ElasticSearch du terme, fait référence à l'ensemble des indices de l'index. L'index ElasticSearch est le container logique de l'ensemble des indices. Gardez toujours à l'esprit que l'index désigne simplement l'ensemble des documents JSON stockés sur le disque. Vous pouvez imaginer l'index ElasticSearch comme une base de données relationnelle et au sein de cette base de données, il y a plusieurs tables, chaque table regroupe l'ensemble des lignes qui possèdent les mêmes colonnes. Dans notre analogie, la base de données serait l'index ElasticSearch, tout comme une base de données n'est qu'une représentation logique du stockage des données, tel l'index ElasticSearch est un container logique des indices. Chaque table de la base de données serait un indice, et tout comme la table n'est qu'une abstraction logique de stockage, ainsi l'indice est le container logique des documents du même type. Chaque table est simplement un ensemble de lignes qui partagent les mêmes colonnes. Dans ElasticSearch, les colonnes seraient le type et chaque ligne correspondrait à un document. L'ensemble des documents qui partagent le même type. Tout comme la base de données est stockée physiquement sur le disque dur non pas sous forme de tables mais comme des fichiers, tel est l'index. L'index est l'ensemble des fichiers JSON stockés sur le disque dur sans aucune abstraction logique. Cette distinction est très importante, car les indices sont traités indépendamment les uns des autres lors des recherches. À cause de cela, on dit d'ElasticSearch qu'il est tenant(2). Le tableau suivant va vous aider à retenir l'organisation des données dans ElasticSearch.
|
SGBDR |
ELASTICSEARCH |
|---|---|
|
Base de données |
Index ElasticSearch |
|
Tables de la base de données |
Indices de l'index ElasticSearch |
|
Colonnes de la table |
Types de l'indice/propriétés des documents JSON |
|
Lignes de la table |
Documents de l'indice |
|
Tableau 10-1 |
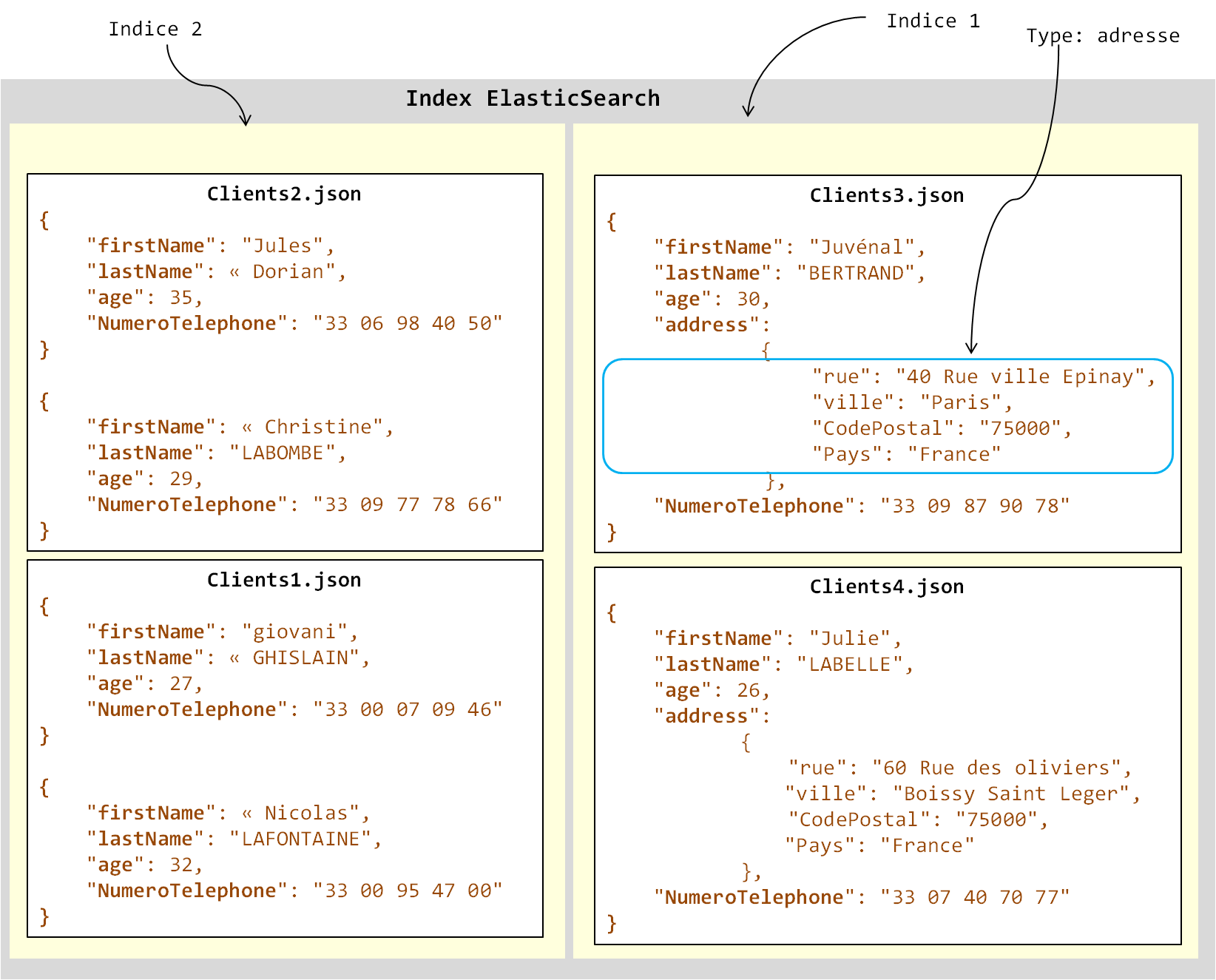
Le type est donc le moyen de séparation des documents dans l'index en groupes logiques. Attention quand même, le type sépare les documents uniquement d'un point de vue logique. Physiquement, les documents appartiennent tous au même index et sont persistés au même endroit sur le disque dur. Tout comme un SGBDR peut supporter plus d'une base de données relationnelle, vous pouvez définir plusieurs index ElasticSearch. Par exemple, dans une instance de SQL Server, plusieurs bases de données peuvent être installées et gérées. Il en est de même avec ElasticSearch. Toute instance d'ElasticSearch peut gérer un ou plusieurs index ElasticSearch. Laissez-nous illustrer tout cela par un exemple. Supposons que nous avons une base de clients constituée de quatre documents JSON dans ElasticSearch. La figure suivante illustre la structure de notre index.
|
|
|
Figure 10-2 |
Structure de l'index ElasticSearch. Tous les documents forment l'index. Dans l'index, les documents sont regroupés par type. Tous les documents qui ont la même structure sont rangés dans le même type (donc dans le même indice).
Comme vous pouvez le voir dans la figure, l'index est l'ensemble des quatre documents. Il est composé des quatre documents JSON Clients1.json, Clients2.json, Clients3.json et Clients4.json. Cependant, les documents clients3.json et clients4.json n'ont pas la même structure que les fichiers clients1.json et clients2.json. Ils possèdent la propriété address en plus qui est elle-même constituée d'un autre objet contenant quatre propriétés (rue, ville, CodePostal et Pays) que nous avons surlignées dans la figure par le rectangle bleu ciel. Pour indexer ces deux documents, l'utilisateur doit obligatoirement spécifier leur type au moment de leur ajout dans le moteur ElasticSearch. Dans la partie suivante, nous allons vous montrer comment. Pour nos besoins, nous avons choisi de nommer ce type adresse. Le type adresse contiendra dans l'avenir tous les documents qui ont la même structure que les documents clients3.json et clients4.json. En créant ce type, ElasticSearch va indexer les quatre propriétés de la propriété address et l'utilisateur pourra effectuer des recherches qui pointent uniquement sur ces quatre propriétés dans l'ensemble des documents du type. Nous allons vous montrer comment dans la partie suivante. Les documents de type adresse sont placés dans l'indice 1. Les deux autres documents sont placés dans l'indice 2. En fait, tout document qui est ajouté dans ElasticSearch doit obligatoirement être placé dans un indice. L'ensemble de ces deux indices forme un index ElasticSearch. Les indices sont ensuite indexés indépendamment les uns des autres. Nous allons maintenant aborder l'architecture d'ElasticSearch et comment celle-ci s'harmonise avec cette organisation de documents.
Les types ne limitent pas les recherches. Une recherche globale qui ne précise pas le type sur lequel effectuer les recherches renvoie tous les documents, peu importe son type. Autrement dit, les recherches ne se font pas sur les types, mais sur tous les documents de l'index. Ainsi, le typage des documents n'affecte pas négativement la précision des recherches lorsque celles-ci ne précisent pas le type sur lequel elles portent.
III-C. Architecture d'ElasticSearch▲
L'approche conceptuelle utilisée par ElasticSearch pour l'indexation et la recherche de contenu conditionne son architecture tout entière. Lorsque vous installez ElasticSearch, vous l'installez par défaut sur une machine. Une instance d'ElasticSearch est démarrée sur cette machine. Cette instance s'appelle un nœud. À l'aide des techniques de virtualisation, vous pouvez démarrer plusieurs instances d'ElasticSearch sur la même machine. Vous pouvez également installer ElasticSearch sur un ensemble de machines configurées en cluster Maître/Esclaves. Dans les deux cas de figure, le cluster ElasticSearch n'est pas égal au nombre de machines ou machines virtuelles sur lesquelles est démarré ElasticSearch, mais à l'ensemble des instances d'ElasticSearch en cours d'exécution. Avec un cluster de nœuds, les activités de stockage, d'indexation et de recherche des documents sont distribuées à travers les nœuds du cluster. Voyons comment cela se fait.
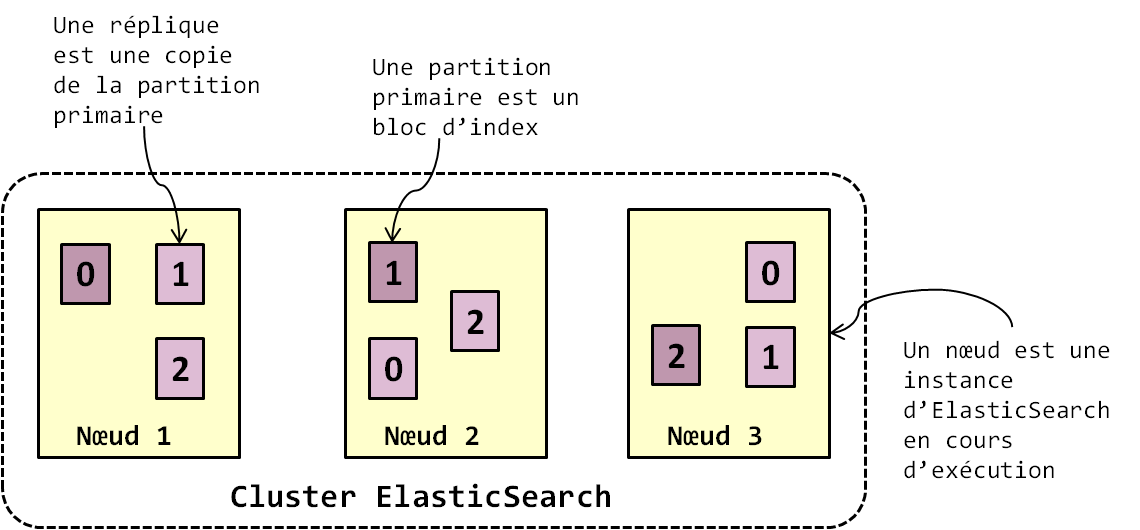
Tout document qui arrive dans un cluster ElasticSearch est placé dans un indice et divisé en partitions (ou shards) selon la méthode round robin (Le SQL dans Hadoop : HiveQL et Pig). Ici, la méthode round robin assure que toutes les partitions auront à peu près la même taille. Les partitions représentent les documents JSON partitionnés en objets de taille à peu près égale. Les partitions sont l'équivalent des divisions des tables relationnelles en blocs de lignes selon une méthode de partitionnement. Le processus de partitionnement affecte également à chaque partition un identifiant. Par défaut, ElasticSearch partitionne les documents en trois partitions. Ces partitions sont ensuite répliquées entre les nœuds du cluster selon un facteur de réplication. Le facteur de réplication par défaut est de 5, en d'autres termes, chaque partition est répliquée 5 fois et ces 5 répliques sont réparties entre les nœuds du cluster. La réplication des données assure la haute disponibilité du cluster et garantit la continuité des traitements en cas de panne dans le cluster. Lors du processus de réplication, ElasticSearch désigne une réplique primaire pour chaque document. Si nous appliquons maintenant les concepts et les principes d'organisation de contenu que nous avons vus dans les deux points précédents, alors il apparaît que les répliques sont en réalité des blocs d'index. La recherche de contenu est faite sur les répliques et comme ElasticSearch est multi-tenant, chaque réplique est considérée comme un index en soi et traitée indépendamment. La figure suivante illustre l'architecture d'ElasticSearch.
|
Figure 10-3 |
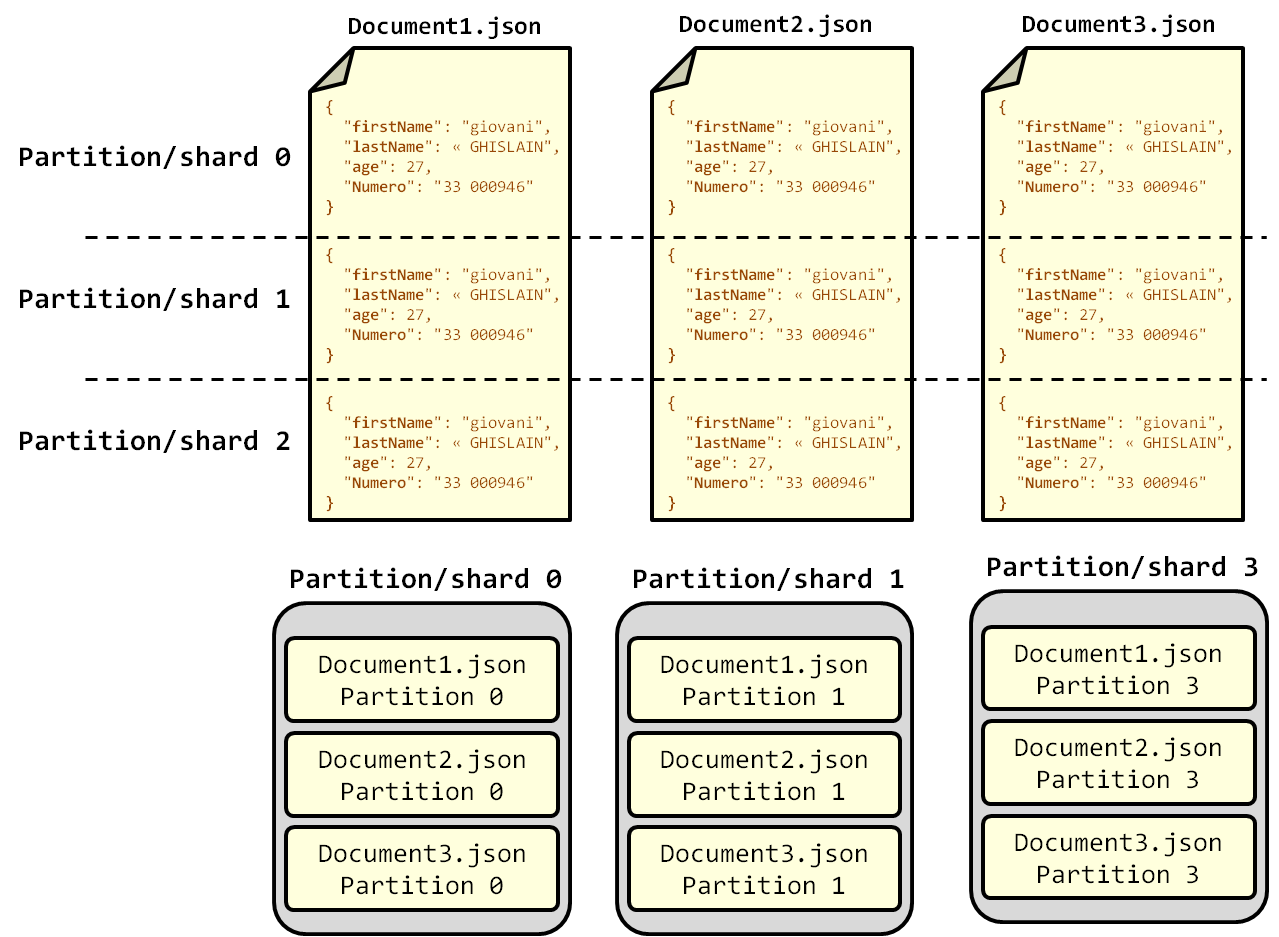
La figure 10-3 met en évidence le fait que l'index (l'ensemble des documents) est divisé en trois partitions (pour chaque document de l'index) auxquelles sont affectés les ID 0, 1 et 2. Attention, il faut comprendre que les partitions ne concernent pas un document, mais bien l'ensemble des documents JSON de l'index. La figure 10-4 suivante illustre parfaitement cela. Les partitions sont ensuite répliquées dans le cluster. La couleur violette foncée dans la figure 52 illustre la réplique primaire de chaque partition. C'est sur ces répliques primaires que les opérations d'indexation et de recherche sont faites avant d'être répercutées sur les autres répliques pour la prise de relai en cas de problème avec la réplique primaire.
|
|
|
Figure 10-4 |
Comme vous pouvez le constater, chaque partition est constituée d'un bloc de chaque document de l'index et stockée sur le disque dur de la machine dans laquelle elle a été assignée. Les partitions sont individuellement indexées, ce qui permet de paralléliser ou de traiter de façon indépendante l'exécution des requêtes de recherche sur les nœuds ElasticSearch. Les partitions représentent des index de plus petite échelle (taille), plus simples à traiter, comparer à l'index original. Vous retrouvez donc là les principes de fonctionnement de Hadoop : le gros fichier est découpé en blocs de petite taille et ces blocs sont traités individuellement par les nœuds du cluster, et ce de façon complètement tolérante aux pannes (Hadoop : la nouvelle infrastructure de gestion de données). ElasticSearch applique exactement le même principe avec les partitions. Techniquement, les partitions sont des index Lucene. Une instance d'Apache Lucene est affectée à chaque partition et ses répliques, et lorsque les requêtes des utilisateurs arrivent dans le système, chaque instance d'Apache Lucene effectue la recherche de contenu sur la partition à laquelle il a été affecté. Apache Lucene est un peu comme la fonction Map qui est attribuée à un bloc de fichier dans Hadoop. Apache Lucene transforme la partition en index inversé et c'est sur cet index inversé de la partition que la recherche de contenu est faite. À ce stade, vous avez compris comment l'indexation de contenu se passe dans ElasticSearch. Il est vraiment important de bien comprendre les principes que nous avons énoncés dans ces deux points si vous souhaitez maîtriser le développement d'application en ElasticSearch. Nous allons maintenant passer à l'étude de la recherche de contenu.
IV. La recherche de contenu dans ElasticSearch▲
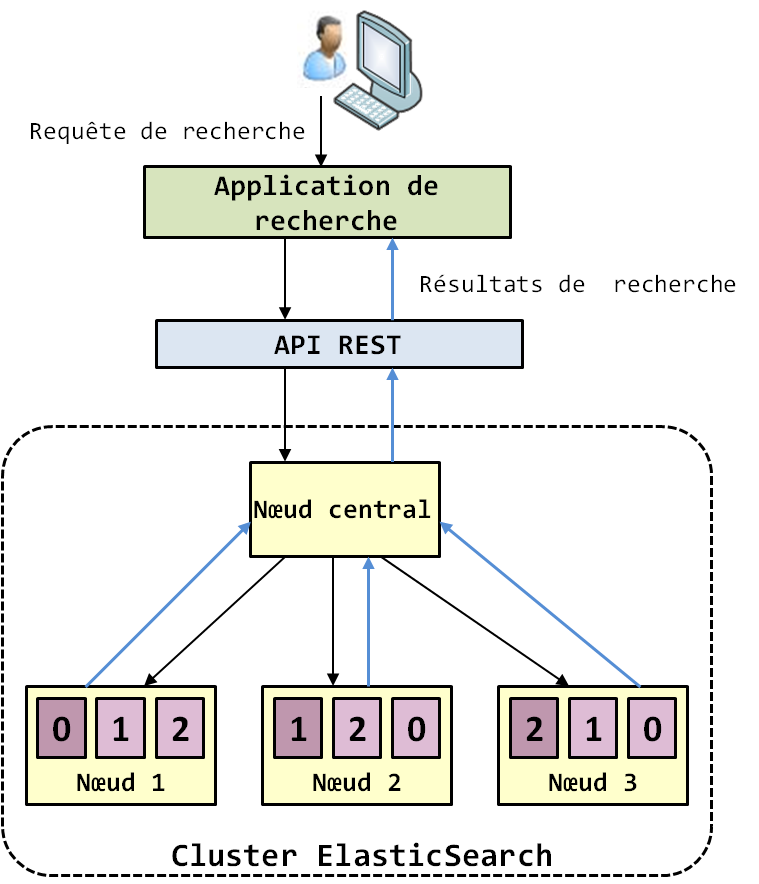
L'avantage de la structure hiérarchique du format JSON est qu'il permet d'indexer tout le contenu des documents. De plus, il facilite la recherche, car celle-ci peut se faire de façon ciblée sur des propriétés précises. Cela signifie que l'utilisateur peut faire des recherches en s'appuyant sur n'importe quelle propriété ou il peut chercher du contenu de façon générale sans indiquer les propriétés qui les contiennent. Lorsque vous effectuez des requêtes de recherche de contenu, ElasticSearch les traite selon le principe suivant : lorsque la requête arrive dans le cluster ElasticSearch, elle est réceptionnée par le nœud maître du cluster, celui-ci la transfère à tous les nœuds qui possèdent une partition de l'index, que ce soit une partition primaire ou une réplique. Ensuite, sur chacun de ces nœuds, une instance d'Apache Lucene qui y tourne effectue l'opération de recherche sur la partition (l'index inversé de la partition) et renvoie les résultats correspondants au nœud maître. Celui-ci réceptionne les résultats de chaque nœud, les agrège et les retourne à l'utilisateur. Étant donné que les partitions ont normalement la même taille avec la méthode round robin, ce principe assure que la charge de calcul des requêtes est équitablement répartie entre les nœuds du cluster. Ce qui est également intéressant avec ElasticSearch à ce niveau est que tout ce processus est complètement transparent à l'application de recherche. L'utilisateur exécute ses requêtes via l'API REST offerte par ElasticSearch sans s'encombrer des détails de coordination et d'exécution de celles-ci dans le cluster. L'API REST joue un peu le même rôle que le SQL dans les SGBDR MPP (Le SQL dans Hadoop - Partie 2 : les moteurs natifs SQL sur Hadoop). C'est cette simplicité qui est l'une des raisons à l'origine du succès de l'adoption d'ElasticSearch. Dans le point qui va suivre, nous allons vous montrer comment manipuler cette API. La figure suivante illustre le processus de recherche de contenu dans ElasticSearch.
Il est important de noter que la recherche se fait aussi sur toutes les répliques des partitions. Puisque les répliques contiennent les mêmes données que les partitions primaires, cela favorise la haute performance des calculs et assure la haute disponibilité du cluster en cas de panne lors des traitements.
|
|
|
Figure 10-5 |
Maintenant que tout est en place, nous allons vous montrer concrètement comment faire de la recherche de contenu sur ElasticSearch via son API REST.
V. Exploitation d'ElasticSearch▲
Vous avez appris tout au long des points précédents les principes de fonctionnement d'ElasticSearch. En réalité, tous ces points n'avaient qu'un seul but : vous préparer à l'utiliser efficacement. Vous avez besoin de connaître ces principes, surtout si vous souhaitez développer des applications qui utilisent ElasticSearch comme moteur d'indexation de contenu. Comme nous l'avons dit précédemment, l'interaction et la recherche de contenu dans ElasticSearch se font à l'aide d'une API REST qu'il fournit. Que vous envisagiez d'intégrer ElasticSearch comme moteur d'indexation de contenu dans une application ou l'utiliser directement, les deux cas se font par le biais de son API REST. Dans cette sous-partie, nous allons vous apprendre à exploiter cette API.
V-A. Les fondamentaux du REST▲
Avant d'entrer dans le vif du sujet, il faudrait d'abord aborder le fonctionnement du REST de façon générale et son rapport avec le JSON et le HTTP, car la compréhension de l'API REST d'ElasticSearch passe par la compréhension du REST. De plus, dans le développement d'applications en Big Data en général et sur Hadoop en particulier, vous rencontrerez et manierez beaucoup les API REST. Par contre, ce point n'est pas pour tout le monde, il est juste pour ceux qui n'ont pas la connaissance élémentaire sur le REST et le fonctionnement du Web de façon générale. Si vous n'êtes pas de ces personnes, alors vous pouvez directement passer au point suivant.
REST est l'acronyme de REpresentational State Transfer, il décrit un style d'architecture logicielle permettant de développer une application devant fonctionner dans une architecture client-serveur, comme c'est notamment le cas sur Internet. REST n'est pas un protocole, mais un standard, une façon de développer une application qui va communiquer dans un modèle distribué (client-serveur)(3). Il a été mis au point en 2000 par Roy Fielding pour faciliter la communication des applications sur Internet. Pour comprendre le standard REST, il est impératif de comprendre comment la communication se passe sur Internet.
V-A-1. Les principes de la communication sur Internet▲
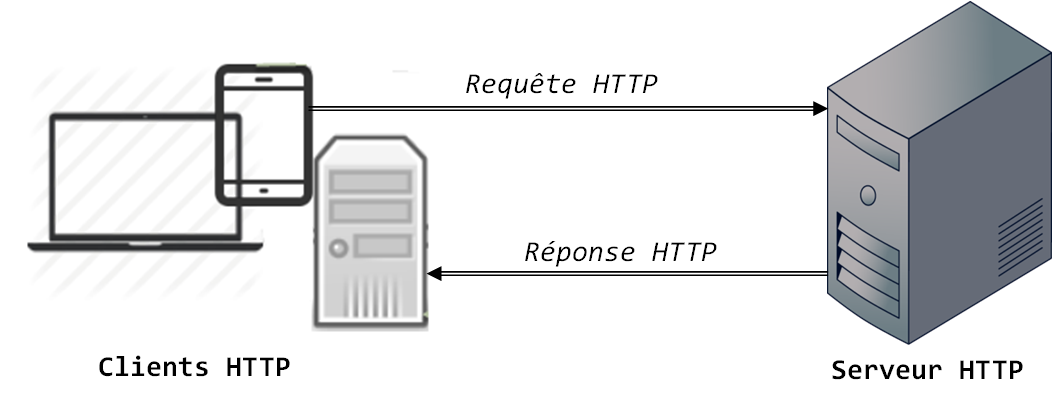
Traditionnellement, l'échange d'information sur Internet se fait à travers un protocole de communication appelé le HTTP (Hyper Text Transfer Protocol). Une machine appelée « Client » (ou client HTTP) envoie une requête HTTP à une machine appelée « Serveur » (ou serveur HTTP) et celle-ci lui renvoie une réponse HTTP.
|
|
|
Figure 10-6
|
Il faut bien comprendre que l'architecture client/serveur ne s'applique pas qu'à Internet, mais aussi aux bases de données, aux imprimantes, et à toute ressource informatique. Le modèle client/serveur permet de centraliser la gestion des ressources informatiques autour d'un serveur. Le client fait une demande et le serveur répond à cette demande en renvoyant une ressource ou une réponse qui peut être une application, le résultat d'un calcul, ou l'exécution d'une action. En fonction de la ressource qu'il renvoie, on distingue différents types de serveurs. Par exemple, on va parler de serveur d'impression si la ressource gérée par la machine serveur est une imprimante, serveur de base de données si la ressource est une base de données, serveur applicatif si la ressource est une application, ou encore serveur web si la ressource est un ensemble de pages web. Prenons un exemple, lorsque vous imprimez un document dans votre entreprise, bien que vous exécutez l'action sur l'imprimante, l'impression ne se passe pas de suite, la requête remonte au serveur qui gère l'imprimante et c'est lui qui déclenche l'action d'impression au niveau de l'imprimante. Ce mode de fonctionnement est bénéfique pour les entreprises parce qu'il facilite l'administration et la gestion de leurs ressources informatiques. La figure suivante illustre le fonctionnement de l'architecture client-serveur de façon large.
|
|

|
Figure 10-7 |
C'est par abus de langage que sur le marché on emploie des expressions comme serveur d'impression, serveur de base de données, ou encore serveur web. En réalité, pour fournir la ressource au client, un logiciel tourne sur la machine serveur et c'est ce logiciel qui gère opérationnellement la ressource. Par exemple, lorsqu'on parle de serveur de base de données, on fait référence à une machine centrale sur laquelle un SGBD comme SQL Server est exécuté et c'est ce SGBD qui, en utilisant la puissance de calcul de la machine est capable de fournir aux clients les données de la base de données. Pareil, lorsqu'on parle de serveur Web, on fait en fait référence à une machine centrale sur laquelle tourne un logiciel de gestion du Web tel qu'Apache WAMP ou Microsoft IIS (Internet Information Services) et c'est lui qui s'occupe de fournir les pages web aux clients. La machine centrale du modèle client-serveur ne peut rien faire sans ce logiciel de gestion de ressources.
Sur Internet, la ressource gérée par le serveur Web (ou serveur HTTP) est l'ensemble des pages web (des fichiers HTML) d'un site Internet. Le client envoie une requête dite HTTP à travers un navigateur Internet tel que Mozilla Firefox, Google Chrome, Internet Explorer, ou autre. Celui-ci le transfère au serveur à travers un protocole de transport de données comme le TCP/IP. Le serveur reçoit la requête et y répond en renvoyant la page web correspondante. La question que nous avons envie de vous poser alors est celle-ci : « comment le serveur est-il capable de renvoyer LA bonne page web au client ? » Tout simple ! La requête du client est spécifiée sous la forme d'une URL (Uniforme Ressource Locator), qu'on appelle communément une adresse Web. Cette URL ou adresse web possède une structure qui permet d'identifier chaque page web de façon unique sur Internet, et qui permet également au serveur de connaître sa localisation sur le disque dur. Cette URL est composée de cinq parties :
- le Protocole de communication (ex. : HTTP, FTP, mail, etc.) ;
- la machine hôte ou serveur web sur lequel la page web est hébergée. On parle souvent de Host pour le désigner (ex. : capgemini.com, localhost, etc.) ;
- le port d'écoute des clients HTTP (ex. : 8080, 80, etc.) ;
- le chemin d'accès sur lequel le fichier est stocké sur le serveur. On parle souvent de Path pour le designer (ex. : /fichiers/fichiers_clients.html) ;
- le fichier HTML de la page web proprement dite (ex. : accueil.html).
La syntaxe typique d'une URL est la suivante : protocole://host:port/path/file.html ou simplement protocole://host/path/file.
Par exemple, supposons qu'en tant que client, nous voulons accéder à la page elasticsearch.html hébergée par le serveur Web de Wikipedia. Nous saisirons sur notre navigateur Web l'adresse suivante : http://fr.wikipedia.org/wiki/Elasticsearch et nous obtiendrons la page web d'ElasticSearch. Vous pouvez configurer votre machine en serveur web en y installant soit WAMP (Windows, Apache, MySQL, PHP), soit IIS (Internet Information Services) de Microsoft. Auquel cas, votre machine sera le Host et son adresse sera la suivante : localhost. Exemple : http://localhost:8080/essai.html. En fait, les requêtes HTTP sont simplement des demandes de page web. Chaque page web s'identifie à l'aide de son URL et le protocole HTTP permet au client et au serveur de communiquer et de s'échanger les informations.
La machine hôte sur laquelle les pages web sont stockées ne s'identifie pas originalement des noms tels que localhost, laposte.net ou google.fr. Ce sont là des noms de domaine. En réalité, la machine hôte s'identifie par son adresse IP. Comme l'adresse IP est compliquée à retenir pour les utilisateurs, c'est le nom de domaine, attribué par le fournisseur d'Internet qui est utilisé à sa place. Par exemple : le nom d'hôte localhost remplace l'adresse IP 127.0.0.1 de la machine. On aurait dû dire http://127.0.0.1:8080/essai.html, mais pour réduire la complexité de l'URL, on change l'adresse IP en nom de domaine, http://localhost/essai.html, ce qui est plus simple à retenir.
Que ce soit sur Internet ou dans une base de données, ou n'importe quel autre domaine, toute communication entre un client et le serveur de ressources en architecture client-serveur passe obligatoirement par un protocole de communication. Dans le cas d'Internet, ce protocole c'est le HTTP, dans le cas d'une base de données, c'est l'ODBC (Open Data Base Connectivity), le JDBC (Java Data Base Connectivity) ou l'OLE DB (Object Linking & Embedding Data Base). Le protocole de communication fournit un ensemble de méthodes (dans le jargon du web, on parle de verbes) qui permettent au client de spécifier l'action qu'il voudrait que le serveur exécute. Les méthodes délimitent les interactions que les clients peuvent avoir avec le serveur et c'est en réalité par leur biais qu'ils communiquent. Ces méthodes se spécifient à l'aide d'un langage de programmation. Dans le cas du protocole HTTP, le langage utilisé c'est le HTML, dans le cas des bases de données relationnelles, le langage c'est le SQL. Le tableau ci-après montre le parallèle entre les méthodes du HTTP et les clauses SQL. Si nous les mettons côte à côte, c'est pour que vous compreniez que les principes qui sont à la base de tous ces systèmes informatiques sont les mêmes. Les noms peuvent changer, les procédés peuvent changer, mais les principes sous-jacents sont les mêmes, et ElasticSearch ne fait pas exception.
|
VERBE HTTP |
CLAUSE SQL |
|---|---|
|
PUT |
|
|
GET |
|
|
POST |
|
|
PATCH |
|
|
DELETE |
|
|
Tableau 10-2. |
Ainsi, une requête HTTP est formellement une méthode + une URL, où la méthode spécifie l'action à exécuter par le serveur sur la page web identifiée par l'URL. Lorsque vous saisissez la requête HTTP suivante dans votre navigateur « http://fr.wikipedia.org/wiki/Elasticsearch », vous êtes implicitement en train de faire un « GET http://fr.wikipedia.org/wiki/Elasticsearch » donc vous êtes en train de demander au serveur Wikipédia de vous renvoyer la page ElasticSearch. Ainsi, le développement des API qui s'appuient sur le protocole HTTP consiste simplement à intégrer ces verbes. Maintenant que vous avez compris les principes de communication sur une architecture client-serveur, et sur Internet, d'où vient l'intérêt du REST ? Pour répondre à cette question, il faut que vous compreniez la notion de service.
V-B. Les services▲
Après la connaissance des principes de communication dans un environnement distribué et sur Internet en général, il vous faut comprendre clairement la notion de service pour être opérationnel avec les API REST. Il y a beaucoup de définitions de service sur le marché, spécialement sur la notion de service Web. Cependant, nous trouvons que ces définitions ne reviennent pas suffisamment en profondeur sur le pourquoi des approches orientées service. À cause de l'utilisation des services dans les applications distribuées et sur Hadoop, nous allons vraiment expliquer dans le détail la notion de service. ElasticSearch n'est pas la seule technologie qui s'appuie sur des approches orientées service telles que l'API REST, Hadoop possède des outils de coordination de service comme ZooKeeper (Tutoriel d'initiation à l'écosystème d'Hadoop), qui s'utilise exclusivement en mode service exposé via une API. Ce point sort de l'étude d'ElasticSearch, mais est un prérequis obligatoire pour son exploitation.
La notion de service dans les logiciels applicatifs vient d'une stratégie d'alignement du Système d'Information aux objectifs de l'entreprise appelée l'urbanisation. Pour une entreprise, urbaniser son système d'information consiste à l'organiser de façon à ce qu'il puisse absorber en continu les évolutions métiers (diversification des offres commerciales, commerce électronique, gestion de la relation client, nouveaux modes ou canaux de distribution, etc.), technologiques (changement de logiciel, nouvelles versions de logiciel) et organisationnelles (Regroupements et fusions, acquisitions, partenariats, réorganisation, externalisation, redéploiement des fonctions de back et front office, etc.) auxquelles fait face l'entreprise, et ce à moindre coût. Pour ce faire, certains auteurs (Longépé, Hermès, Saassoon) proposent de considérer l'activité de l'entreprise comme un processus de production global qui se déroule en mettant en œuvre des traitements répartis dans différentes « zones ». Ainsi, urbaniser son système d'information revient à le découper en zones interdépendantes.
Le Système d'Information traduit la façon dont une entreprise acquiert, stocke, traite et diffuse les données au sein de l'entreprise. Ce système a pour support le système informatique qui lui-même n'est que l'orchestration d'un ensemble de technologies. Ces technologies déterminent l'efficacité du Système d'Information et l'efficacité du Système d'information va déterminer la performance de l'entreprise. Étant donné que le système informatique est l'infrastructure du système d'information, le « zonage » du système d'information entraîne nécessairement un « zonage » équivalent du système informatique. Une zone a pour équivalence en logiciel applicatif un service. Ainsi, zoner son système informatique revient à le réorganiser sous forme de services interopérables. La démarche SOA est la démarche à suivre pour garantir cette interopérabilité des services. Le SOA (Services Oriented Architecture), littéralement Architecture Orientée Services, est une démarche d'urbanisation qui consiste à organiser l'architecture du système informatique d'une entreprise comme un ensemble services interopérables. Le SOA est fondamental lorsqu'on veut tirer meilleur profit des technologies.
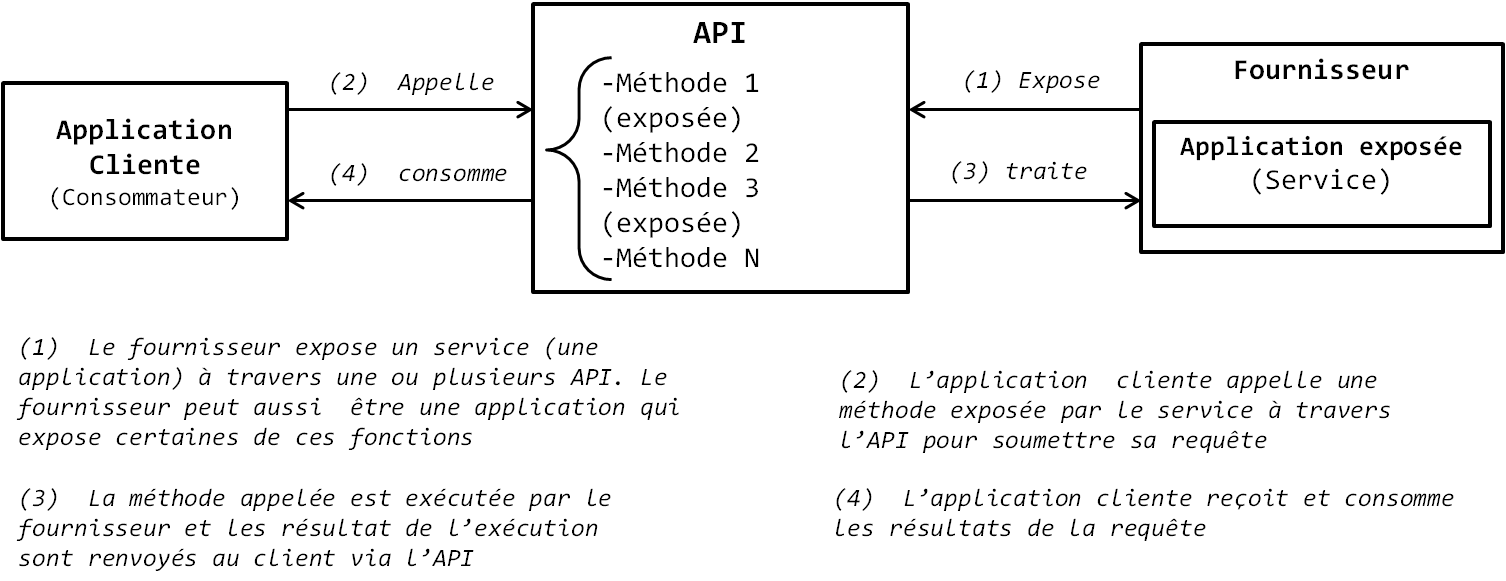
Le principe d'urbanisation est le suivant : un fournisseur offre un service à un client qui le consomme dans une relation de confiance établie entre les deux parties. Le client utilise (consomme dans le jargon) le résultat offert par le service sans se soucier de savoir comment ce dernier est obtenu. La démarche SOA suit ce même principe. Le service est une action exécutée par un fournisseur (producteur dans le jargon) à l'attention d'un client (consommateur dans le jargon) selon un contrat. Le Client est simplement utilisateur du service, il utilise le service sans savoir comment il est implémenté. Le client peut être un logiciel, un programme ou un autre service, qui fait appel aux fonctionnalités d'un autre logiciel. Le logiciel qui fournit ses fonctionnalités représente le producteur, tandis que les fonctionnalités offertes par le logiciel représentent les services offerts.
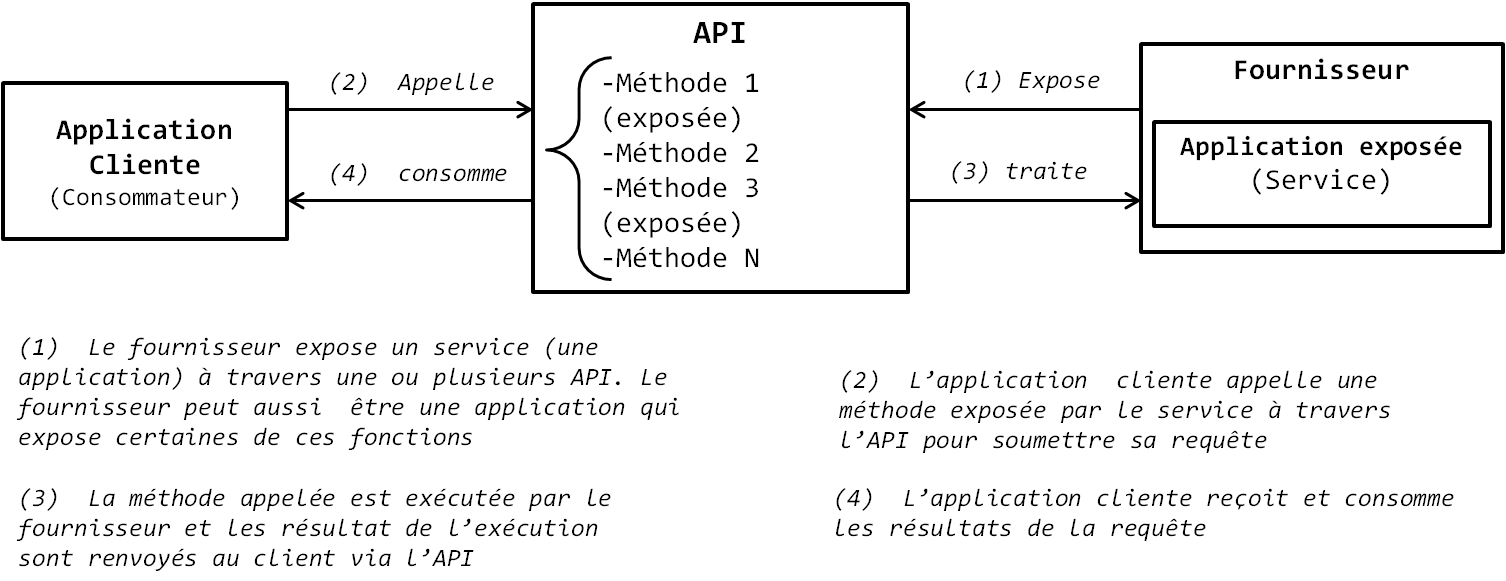
Nous allons illustrer tout ce qui a été dit plus haut sur les services par un exemple. Supposons que vous développez une application logicielle de gestion de stocks et que dans cette application vous avez besoin d'implémenter des fonctions de géolocalisation. Au lieu de développer vous-même les fonctions de géolocalisation dans votre application, vous faites appel à Google et implémentez son service de géolocalisation Google Earth dans votre logiciel via un ensemble d'API offertes par Google. Dans ce cas de figure, votre application est un client de Google, Google Earth est le service offert, et Google est le fournisseur. Votre application ne sait pas comment Google Earth fournit les fonctionnalités du service, elle ne fait que consommer les résultats de ces fonctionnalités à travers les API fournies. Une API (Application Programming Interface, littéralement Interface de Programmation Applicative) est une interface, une sorte de pont de connexion entre deux applications, dans lequel sont exposées un ensemble de méthodes à utiliser pour faire appel aux fonctionnalités offertes par le service. C'est l'ensemble des fonctionnalités offertes par le service qui est qualifié de contrat. L'API est le contrat passé entre le fournisseur de service et le client. Il définit ce que le client peut ou ne peut pas faire. L'API se présente sous forme d'une classe et chaque méthode se présente sous forme d'une fonction qui expose une fonctionnalité précise du service. Un fournisseur peut décider d'exposer une ou plusieurs méthodes de son service, par exemple un service peut avoir dix méthodes dans son ensemble, mais le fournisseur décide d'exposer ou d'en rendre public (dans le jargon technique) que trois. Le client n'utilise le service que par appel des méthodes exposées dans l'API. C'est pourquoi on dit dans la littérature informatique qu'une API est un contrat, le contrat d'utilisation du service. L'avantage de cette approche architecturale est qu'elle vous évite d'avoir à développer vous-même et maintenir des fonctionnalités qui ne sont pas au cœur du besoin métier que votre application implémente. Avec ElasticSearch et beaucoup d'autres applications de l'écosystème Hadoop, c'est le cas : vous développez une application qui exploite des fonctionnalités exposées, ce qui vous évite d'avoir à gérer vous-même dans l'application la complexité de l'exécution distribuée. Ainsi, la démarche orientée services (SOA) est une démarche très efficace pour répondre aux besoins d'interopérabilité et de réutilisabilité de différentes applications. La figure suivante illustre l'architecture de fonctionnement d'un logiciel développé selon une approche orientée services.
|
|
|
Figure 10-8 |
Attention tout de même à ne pas confondre une API avec un protocole. Un protocole est une spécification, un langage qui permet à deux ou plusieurs ordinateurs ou applications de communiquer, tandis que l'API expose les méthodes qui leur permettent de communiquer. Dans la démarche orientée services, l'application cliente et le fournisseur sont capables de communiquer uniquement si le client est compatible avec le protocole du fournisseur du service. Prenons l'exemple d'un protocole classique : l'ODBC (Open Data Base Connectivity). Ce protocole est le standard utilisé pour connecter un serveur de base de données et un client. Supposons que vous développez une application en Visual BASIC et vous utilisez l'API ADO (ActiveX Data Objects) qui expose certaines fonctionnalités d'une base de données Oracle. Si la base Oracle n'est pas compatible avec le protocole ODBC, alors même si l'API ADO que vous utilisez expose les fonctionnalités de la base Oracle, votre application Visual Basic ne pourra pas se connecter avec la base de données Oracle. Pour que deux applications puissent se connecter, il faut obligatoirement qu'elles soient compatibles avec le même protocole de communication. En fait, c'est le protocole qui permet de définir les deux types de services qui existent actuellement : les services que nous allons qualifier d'« applicatifs », qui s'appuient sur des protocoles applicatifs comme le JDBC, l'ODBC, ou encore l'OLE DB ; et les services web, qui s'appuient sur les protocoles Web tels que le HTTP et qui permettent d'appeler des services depuis Internet. La différence avec les services applicatifs est que la compatibilité de protocole entre les clients et les fournisseurs de service n'est plus nécessaire puisque le fournisseur du service est distant, accessible par un protocole web ; dans ce cas de figure, l'API offerte par le service continue d'être le contrat, mais n'est plus le canal par lequel le client envoie ses requêtes et reçoit les réponses, plutôt il utilise un format d'échange de fichier, le XML (de plus en plus utilisé), ou le JSON pour décrire ses requêtes et recevoir ses réponses. Voilà ! Ce petit condensé sur les services va vous permettre de mieux comprendre le REST, l'utilisation d'ElasticSearch et l'impact de la démarche orientée services sur les applications distribuées.
V-C. Le REST▲
À ce stade, tous les éléments sont réunis pour que vous ayez la maîtrise du REST. Dans ce point, nous n'allons pas entrer dans les spécificités du REST, nous allons juste expliquer les principes fondamentaux nécessaires pour utiliser une API REST. Comme nous l'avons dit à l'introduction de cette partie, REST est un modèle d'architecture d'applications orientées services devant fonctionner dans un environnement distribué de type client-serveur. Pour faire simple, REST est un ensemble de bonnes pratiques à respecter pour développer des services. Il a été mis au point au départ pour le développement des services Web (Roy Fielding, l'auteur du REST, est un des principaux créateurs du HTTP), mais après avoir lu ce que nous avons exposé précédemment, vous comprenez que le REST peut s'utiliser aussi bien pour les services Web que pour les services applicatifs. Les services qui sont basés sur l'architecture REST sont appelés les services RESTful. Ainsi, lorsque vous entendrez RESTful, sachez qu'il s'agit d'un service qui respecte les principes de l'architecture REST.
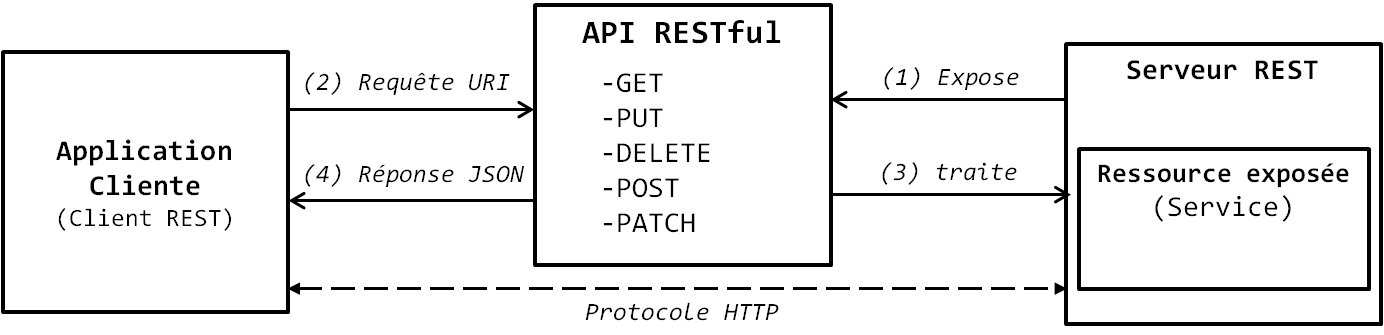
Dans l'architecture REST, le modèle de communication reste le modèle client-serveur : des clients REST font la demande d'une ressource à un serveur REST qui leur en fournit l'accès. Les ressources sont identifiées de façon unique par leur URI (Uniform Ressource Identifier) et s'accèdent à l'aide des méthodes du protocole HTTP. Tout comme dans le Web le format d'échange utilisé pour transmettre les réponses aux requêtes HTTP est le HTML, dans le REST, le format d'échange utilisé pour transférer les ressources est le JSON (le XML est aussi souvent utilisé). Ainsi, l'API d'un service RESTful expose les fonctionnalités d'une application sous forme de ressources accessibles à l'aide de simples méthodes GET, PUT, POST, DELETE ou PATCH. La force du REST vient du fait qu'il s'appuie sur le protocole HTTP pour la communication entre le client REST et le serveur REST, ce qui fait de lui une alternative efficace aux autres protocoles de communication à distance tels que le RPC (Remote Procedure Call) utilisé en MapReduce pour le transfert des données des nœuds Map pour les nœuds Reduce.
REST considère chaque objet exposé comme une ressource. Le terme « ressource » dans le REST est un concept similaire à un objet en programmation orientée objet ou à une entité dans le MCD d'une base de données. Il représente tout élément qui peut être nommé et référencé par un lien hypertexte, tel qu'un fichier, une page HTML, une image, une vidéo, etc. Il est donc important de garder à l'esprit que la réponse renvoyée par le serveur REST n'est pas la ressource elle-même, mais sa représentation. Cette représentation s'appuie sur un format de fichier tel que le JSON. Ainsi, lorsque vous faites la requête d'une ressource, vous obtenez un fichier JSON décrivant cette ressource. Par contre, l'API RESTful par laquelle vous accédez à la ressource la manipule réellement. La ressource est identifiée de façon unique à l'aide d'une URI qui s'écrit selon la syntaxe suivante : protocole://host:port/Ressources/RessourceID ou simplement protocole://host/Ressources/RessourceID. Aussi, il n'est pas rare de voir des architectures REST présentant les URI selon cette syntaxe :
protocole://host/Ressources?method=nom_de_methode¶m=parametre_de_methode
La ressource s'accède à l'aide de son URL via un verbe du protocole HTTP. La figure suivante illustre tout ce que nous venons de dire sur le REST en relation avec les services.
|
|
|
Figure 10-9 |
Illustrons tout ce que nous avons dit sur les services RESTful par un exemple afin que ce soit plus concret pour vous. Supposons que nous souhaitons réaliser un service REST pour gérer les livres d'une bibliothèque. Le service doit nous permettre de pouvoir ajouter, modifier, lire et supprimer ces livres. Les livres constituent la ressource à manipuler. Supposons que le serveur a pour adresse
http://bibliotheque/. Les livres auront pour URI : http://bibliotheque/livres/livre_id. À l'aide d'un outil comme postman, on pourrait adresser les requêtes suivantes :
- lire le livre 4 : « GET http://bibliotheque/livres/4 » ;
- modifier le livre 10 : « POST http://bibliotheque/livres/10 » ;
- supprimer le livre 5 : « DELETE http://bibliotheque/livres/5 ».
Vous avez maintenant toutes les armes en main pour comprendre comment exploiter ElasticSearch. N'hésitez pas à relire ces points, car la maîtrise des principes qui y sont exposés vous servira pour aborder aisément les prochains points du tutoriel.
VI. Utilisation d'ElasticSearch▲
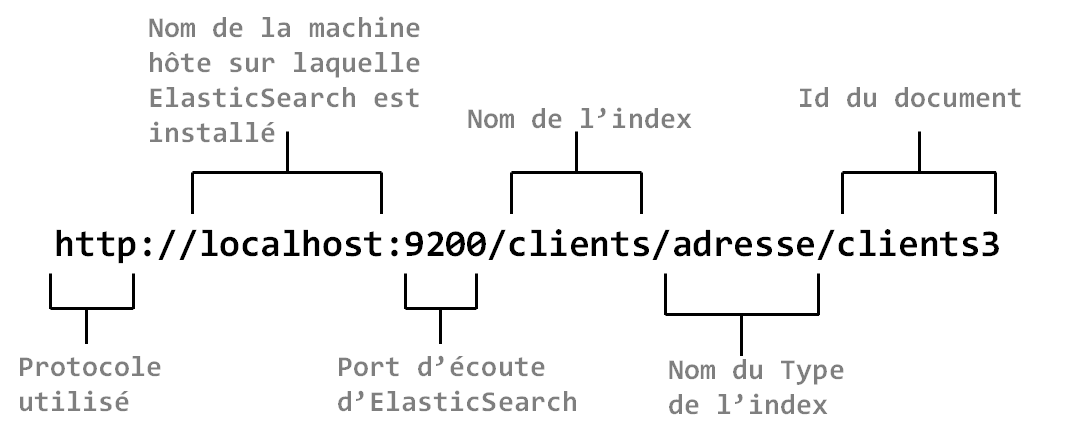
Comme nous avons dit précédemment, ElasticSearch s'exploite à l'aide d'une API REST. En d'autres termes, lorsque vous développez une application de recherche de contenu qui s'appuie sur ElasticSearch, vous exploiter simplement l'API par laquelle il expose ses fonctionnalités. La ressource exposée ici c'est l'index, ElasticSearch joue le rôle du Serveur REST et vous manipulez les documents de l'index à l'aide des verbes HTTP. Le JSON est utilisé comme format d'échange de données. L'URI de l'index a la forme suivante : protocole://host [:port]/index/type/document_id
La figure suivante illustre les différentes parties d'une URI d'index ElasticSearch.
|
|
|
Figure 10-10
|
Localhost est le nom de l'hôte lorsque vous avez installé ElasticSearch sur votre machine. Auquel cas, le port d'écoute est 9200. Dans ce tutoriel, nous aborderons l'installation d'ElasticSearch afin d'éviter d'entrer dans les détails techniques et les configurations nécessaires liés aux différents systèmes d'exploitation. Pour plus de détails sur l'installation d'ElasticSearch, rendez-vous sur https://www.elastic.co/downloads/elasticsearch
Pour utiliser l'API REST d'ElasticSearch et lui transférer les requêtes HTTP des URI, vous pouvez utiliser des outils comme postman (https://www.getpostman.com/) ou cURL (https://curl.haxx.se/). Mais nous vous recommandons d'utiliser cURL, car il est devenu l'outil par définition d'exploitation d'ElasticSearch. cURL est un utilitaire de ligne de commande qui permet de transférer les données à travers le protocole HTTP. Nous n'allons pas entrer sur les raisons qui font qu'il est devenu un standard dans l'utilisation d'ElasticSearch. Si vous avez installé ElasticSearch sur votre poste et que votre système d'exploitation est Windows, alors pour utiliser cURL, il est préférable d'installer l'outil Cygwin (https://www.cygwin.com/). C'est avec cURL démarré sur Cygwin que nous fonctionnerons tout au long de ce point. La figure suivante illustre la syntaxe de la ligne de commande nécessaire en cURL pour envoyer des requêtes à ElasticSearch.
|
|

|
Figure 10-11 |
L'action exprime le type d'opération qui va être réalisé. Dans le cas de figure, il s'agit d'une recherche de contenu (_search). La requête s'exprime en format JSON. Dans la figure 10-11, la requête consiste à effectuer une recherche de tous les documents de l'index Clients dont la propriété firstname est « juvenal ».
Après avoir installé ElasticSearch sur votre ordinateur personnel, exécutez la commande suivante : curl 'http://localhost:9200'
Vous devriez normalement obtenir une réponse JSON similaire à l'objet JSON suivant :
{
"name": "KL-Mjpy",
"cluster_name": "elasticsearch",
"cluster_uuid": "9Cptxt3fQke7MK-WldD1Uw",
"version": {
"number": "5.1.2",
"build_hash": "c8c4c16",
"build_date": "2017-01-11T20:18:39.146Z",
"build_snapshot": false,
"lucene_version": "6.3.0"
},
"tagline": "You Know, for Search"
}Vous voyez dans les résultats la version de Lucene qui est intégrée à ElasticSearch ("lucene_version": "6.3.0"). Nous allons maintenant créer l'index constitué des quatre fichiers JSON de la figure 10-2. Pour ce faire, la première chose consiste à créer l'index Clients en utilisant la commande suivante : curl -XPUT 'http://localhost:9200/clients'
Attention ! L'index doit être en minuscule, sinon ElasticSearch générera une erreur. Une fois que l'index a été créé, vous obtiendrez la réponse suivante, qui indique le succès de l'opération.
Regardons les caractéristiques par défaut de l'index que nous venons de créer. Cela se fait par la commande suivante :
curl -XGET 'http://localhost:9200/clients'
La réponse à la requête montre que par défaut, l'index est partitionné en cinq et chaque partition est répliquée une fois ("number_of_shards": "5", "number_of_replicas": "1").
{
"clients": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"creation_date": "1485532333694",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "YNRWdEchTPGdAgPn5_tUPA",
"version": {
"created": "5010299"
},
"provided_name": "clients"
}
}
}
}Nous allons maintenant ajouter les fichiers clients1.json et clients2.json dans l'index dans un type que nous appellerons « simple ».
curl -XPUT 'http://localhost:9200/clients/simple/clients2' –d '
{
"client2": [
{
"firstName": "Jules",
"lastName": "Dorian",
"age": "35",
"NumeroTelephone": "33 06 98 40 50"
},
{
"firstName": "Christine",
"lastName": "LABOMBE",
"age": "29",
"NumeroTelephone": "33 09 77 78 66"
}
]
}'
curl -XPUT 'http://localhost:9200/clients/simple/clients1' –d '
{
"client1" : [
{
"firstName": "giovani",
"lastName": "GHISLAIN",
"age": "27",
"NumeroTelephone": "33 00 07 09 46"
},
{
"firstName": "Nicolas",
"lastName": "LAFONTAINE",
"age": "32",
"NumeroTelephone": "33 00 95 47 00"
}
]
}'Vous pouvez vous amuser à émettre une requête GET sur ces deux documents pour voir comment ils sont enregistrés dans l'index. Nous allons maintenant ajouter les fichiers clients3.json et clients4.json dans le type « adresse ».
curl -XPUT 'http://localhost:9200/clients/adresse/clients3' –d '
{
"firstName": "Juvénal",
"lastName": "BERTRAND",
"age": 30,
"address":
{
"rue": "40 Rue ville Epinay",
"ville": "Paris",
"CodePostal": "75000",
"Pays": "France"
},
"NumeroTelephone": "33 09 87 90 78"
}'
curl -XPUT 'http://localhost:9200/clients/adresse/clients4' –d '
{
"firstName": "Julie",
"lastName": "LABELLE",
"age": 26,
"address":
{
"rue": "60 Rue des oliviers",
"ville": "Boissy Saint Leger",
"CodePostal": "75000",
"Pays": "France"
},
"NumeroTelephone": "33 07 40 70 77"
}'Lorsque les documents sont épaves et dispersés, ou lorsqu'un fichier est beaucoup trop volumineux pour que vous le placiez en corps de requête, un simple PUT ne suffit plus pour les placer dans ElasticSearch. Dans ce cas de figure, vous pouvez utiliser la fonctionnalité de chargement par lot introduit avec _bulk par ElasticSearch. Si vous n'arrivez pas toujours à charger vos données dans l'index jusque-là, alors nous vous recommandons d'utiliser Logstash. Logstash est un peu comme un ETL, introduit dans la suite ELK d'Elastic, il permet de se connecter à différentes sources de données, de les transformer et de les charger dans ElasticSearch.
Nous allons maintenant faire des recherches de contenu sur les quatre documents que nous avons ajoutés dans l'index clients. ElasticSearch, en dehors des fonctionnalités de recherche d'Apache Lucene, supporte plusieurs types de recherche tels que la recherche facettée, la recherche booléenne, et la recherche textuelle intégrale entre autres. Pour plus de détails sur ses capacités de recherche, rendez-vous sur son site web officiel. Supposons que dans notre exemple, nous voulons renvoyer tous les documents qui contiennent « Boissy Saint Léger ». Le script suivant effectue la recherche.
curl -XPOST ' http://localhost:9200/clients/adresse/_search –d '
{
"query" : {
"query_string" : { "query":"Boissy Saint Leger"}
}
}'Cette requête fournit le résultat suivant. Les résultats d'une requête de façon générale sont stockés dans l'objet hits. Souvenez-vous, hits est la classe d'Apache Lucene qui renvoie les résultats classés par ordre d'importance. Sa présence dans les résultats montre bien que c'est Apache Lucene qui effectue les opérations de recherche.
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "clients",
"_type": "adresse",
"_id": "clients4",
"_score": 1,
"_source": {
"firstName": "Julie",
"lastName": "LABELLE",
"age": 26,
"address": {
"rue": "60 Rue des oliviers",
"ville": "Boissy Saint Leger",
"CodePostal": "75000",
"Pays": "France"
},
"NumeroTelephone": "33 07 40 70 77"
}
}]Supposons maintenant que nous voulons récupérer tous les documents dont la ville est Paris.
curl -XPOST ' http://localhost:9200/clients/adresse/_search –d '
{
"query" : {
"match" : {
"ville" : "Paris" } }
}
"hits": [
{
"_index": "clients",
"_type": "adresse",
"_id": "clients3",
"_score": 1,
"_source": {
"firstName": "Juvénal",
"lastName": "BERTRAND",
"age": 30,
"address": {
"rue": "40 Rue ville Epinay",
"ville": "Paris",
"CodePostal": "75000",
"Pays": "France"
},
"NumeroTelephone": "33 09 87 90 78"
}
}]Comme vous aurez pu le constater, effectuer des recherches en ElasticSearch signifie maîtriser la syntaxe de l'instruction _search et la construction du corps de la requête. Pour en savoir plus, rendez-vous sur le site https://www.elastic.co/fr/.
VII. En résumé▲
Le Numérique est une ère résolument tournée vers la valorisation et l'exploitation de la donnée. Dans la plupart des cas, ces données sont centralisées dans des bases de données exploitées encore dans une grande majorité de cas par des systèmes de gestion de bases de données relationnelles. Les SGBDR, en s'appuyant sur le SQL, offrent des fonctionnalités de recherche de contenu qui sont très limitées. La récupération des données est malheureusement synonyme des requêtes ayant une forme similaire à celle-ci :
2.
3.
4.
5.
6.
7.
8.
9.
10.
SELECT
co.*, cl.*
FROM
Commandes as co, Clients as cl
WHERE
cl.client_ID = co.cmd_ID AND
co.date_cmd > to_date('2016-09-09', 'yyyy-mm-dd') AND
UPPERCASE(cl.client_Name) = 'CHOKOGOUE' AND
LOWERCASE(cl.client_FirstName) = 'Juvénal' AND
Co.produit LIKE '%big data%';
Hélas, comme vous pouvez le constater vous-même, le SQL n'est pas efficace lorsqu'il s'agit d'exprimer des requêtes d'une certaine complexité et dégrade même la performance du système avec l'augmentation du volume de données dans la base. C'est pour résoudre ce problème que les moteurs d'indexation de contenu ont été créés. Apache Lucene est à la base de tous ces moteurs, il permet de développer des applications qui retrouvent efficacement l'information sur la base des critères aussi bien objectifs que subjectifs. Cependant, avec les exigences de montée en charge et de haute disponibilité requises pour gérer l'explosion du volume de données qui caractérise l'ère Numérique, Apache Lucene s'est montré insuffisant, et c'est là où vient ElasticSearch. Ce tutoriel a eu pour objectif de vous aider à monter en compétence sur ElasticSearch, de pouvoir y être opérationnel de suite. Il en ressort qu'ElasticSearch est un moteur d'indexation de contenu très flexible, scalable et simple à utiliser pour développer des applications de recherche de contenu de moyenne ou large échelle. Grâce à la flexibilité de son concept d'index, de son API REST, de l'utilisation du format JSON et de son intégration à Apache Lucene, ElasticSearch permet à des utilisateurs métier de facilement intégrer à des applications, de puissantes fonctionnalités de recherche de contenu. L'utilisateur n'a ni besoin d'utiliser le Java ni besoin d'ajouter à son infrastructure un support pour le stockage de la base de données, il s'appuie juste sur de simples verbes du protocole HTTP pour indexer et rechercher du contenu dans ses données, et sur l'API REST pour intégrer ces fonctionnalités dans son application. Étant donné sa relative jeunesse, ElasticSearch évolue très vite, spécialement sur son concept d'index. La société Elastic améliore sans cesse la structure d'indexation des données dans ElasticSearch pour l'adapter à de nouvelles problématiques métier. Ainsi, ne soyez pas saisis d'étonnement que le tableau 11 ne soit plus une image fidèle du concept d'index d'ElasticSearch à un moment donné.
Ce tutoriel est extrait de l'ouvrage « Maîtrisez l'utilisation de l'écosystème Hadoop ». Si vous souhaitez allez plus loin dans le développement de vos compétences sur les technologies de l'écosystème Hadoop, n'hésitez pas à vous procurer l'ouvrage en cliquant sur le lien suivant : Maîtrisez l'utilisation de l'écosystème Hadoop. Vous y développerez des compétences sur 18 technologies clés de l'écosystème Hadoop, notamment Apache Lucene, l'indexation de contenu, Spark, Oozie, Hadoop et bien d'autres.
VIII. Mini-Guide de validation des acquis de compétences▲
Si vous le souhaitez, vous pouvez échanger vos réponses avec nous. Pour ce faire, il vous suffit de nous adresser vos réponses à l'adresse mail suivante :
Question : un nœud ElasticSearch correspond à :
- Une machine
- Un nœud dans le cluster
- Une instance d'exécution d'ElasticSearch
Question : un cluster ElasticSearch peut être contenu dans une seule machine
- Vrai
- Faux
Question : des 6 propositions suivantes, cochez celles qui décrivent au mieux le REST
- Un système d'architecture
- Une approche pour construire une application
- Un protocole
- Un format
- Un standard
Question : des 8 activités suivantes, cochez les activités qui sont réalisées par ElasticSearch ?
- Acquisition de document
- Structuration de contenu
- Analyse de contenu
- Indexation de contenu
- Construction de requête
- Exécution de requête
- Restitution de résultat
- Interface utilisateur
Question : dans le schéma suivant, la méthode 2 peut être appelée par l'application cliente.
|
|
- Vrai
- Faux
Question : comment utilise-t-on un service ?
……………………………………………………………………………………………………………………………………………………………….
…………………………………………………………………………………………………………………………………………………………
Question : cochez la bonne réponse. Lors de l'utilisation d'un service
- L'application cliente consomme les fonctionnalités du service
- L'application cliente consomme les résultats des fonctionnalités du service
- L'application cliente consomme l'API offerte par service
Question : cochez la bonne réponse. Lors de l'utilisation d'un service, les méthodes appelées sont
- Exécutées par l'application cliente
- Exécutées par l'application Fournisseur
- Exécutées par l'API
Question : décrivez le résultat de la requête suivante :
curl -XPOST ' http://localhost:9200/clients/adresse/_search –d '
{
"query" : {
"match" : {
"nom" : "juvénal" } }
}………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………………………….
Question : soit un cluster ElasticSearch installé en local sur une machine.
Écrivez la requête HTTP qui permet de créer un index appelé « books »
…………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………
Écrivez la requête HTTP qui permet d'ajouter « book1 » dans le type « computer » de l'index « books»
…………………………………………………………………………………………………………………………………………………………………
…………………………………………………………………………………………………………………………………………
IX. Note de la rédaction developpez.com ▲
Ce cours est un extrait du livre intitulé Maîtrisez l'utilisation de l'écosystème Hadoop.
La rédaction de developpez.com tient à remercier Juvénal CHOKOGOUE qui nous a autorisés à publier ce cours. Nos remerciements également à f-leb pour la relecture orthographique de ce tutoriel.